
近年、ディープラーニングやニューラルネットワークの技術が急速に進展しています。これらの技術の背後には、さまざまなアルゴリズムや関数が存在し、それぞれの役割や特性を理解することで、モデルの性能を向上させることができます。特に、「活性化関数」として知られる関数群は、ネットワークの学習能力や効率を大きく左右します。
本記事では、活性化関数の中でも特に注目される「ReLU関数」と「シグモイド関数」に焦点を当て、その基本的な性質、違い、そしてどのようなシナリオでの使用が最適かを徹底的に解説します。ディープラーニングを学び始めたばかりの方から、さらなる知識を求める上級者まで、幅広くご活用いただける内容となっております。
はじめに:活性化関数の役割

現代のディープラーニングやニューラルネットワークの実装には欠かせない要素が「活性化関数」です。この記事では、その中でも特に有名なReLU関数とシグモイド関数の違いに焦点を当てて解説しますが、まずは活性化関数が持つ役割について理解を深めていきましょう。
活性化関数は、ニューラルネットワークにおける各ニューロンの出力値を決定する役割を持ちます。簡単に言うと、ニューロンが「どれだけの情報を次の層に伝達するか」を決定する関数です。これにより、ニューラルネットワークは非線形性を持つことができ、複雑な関数やデータの特徴を捉える能力が向上します。
基本的な活性化関数の紹介
ニューラルネットワークの世界には、様々な活性化関数が存在します。それぞれの関数は異なる特性や利点を持ち、使用する問題や目的によって選択されます。
シグモイド関数
シグモイド関数は、0から1の範囲の出力を持ち、特に二値分類問題の出力層でよく使われます。古典的な活性化関数の一つであり、シグモイド曲線のS字型の特徴があります。
ReLU関数
近年のディープラーニングの発展に大きく寄与しているのが、ReLU(Rectified Linear Unit)関数です。負の値を0にする一方で、正の値はそのまま出力する特性があります。これにより、計算が高速で、勾配消失問題を緩和する効果も期待されています。
タンジェントハイパボリック関数(tanh)
シグモイド関数と似た形状を持ちながら、出力範囲が-1から1となる関数です。特定のシナリオでの学習がシグモイド関数よりも効率的となることが知られています。
ステップ関数
主にパーセプトロンで使用される関数で、ある閾値を超えたら1を、それ未満なら0を出力します。線形分類の基本となる関数です。
以上のように、活性化関数は多岐にわたります。ReLU関数とシグモイド関数の違いを理解する前に、これらの基本的な特性と用途を知ることは非常に有益です。
シグモイド関数の概要

シグモイド関数は、活性化関数の中で非常に古典的かつ広く使われているものの一つです。その名前が示す通り、この関数の形状は「S字型」になっており、多くの人々に親しまれています。
シグモイド関数の数式と特性
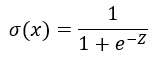
この数式の通り、シグモイド関数の出力は0から1の範囲に収まります。これにより、確率としての解釈が容易であり、二値分類問題の出力層でよく利用されます。
シグモイド関数の利点と制約
シグモイド関数の最大の利点は、その滑らかな形状にあります。この特性により、微分が簡単であり、初期のニューラルネットワークの学習に非常に役立ってきました。一方、深いネットワークにおいては勾配消失問題が生じる可能性があり、これがシグモイド関数の制約として知られています。
ReLU関数の概要

近年、ReLU関数(Rectified Linear Unit)はディープラーニングのフィールドで非常に注目を浴びています。そのシンプルな特性が、高速な学習と高い表現力をもたらす要因となっています。
ReLU関数の数式と特性
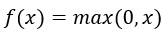
この数式が示す通り、ReLU関数は負の入力値に対しては0を、正の入力値に対してはそのままの値を出力します。この非線形性が、ニューラルネットワークの表現力を高める要因となります。
ReLU関数の利点と制約
ReLU関数の最大の利点は、計算の高速さと、深いネットワークにおける勾配消失問題を緩和する能力です。しかし、ニューロンが死んでしまう「死亡ReLU」問題など、注意すべき点もあります。
主な違い1:出力の範囲

シグモイド関数とReLU関数、両方の活性化関数には独自の出力範囲が存在します。これらの範囲は、関数の特性や用途を大きく影響します。
シグモイド関数の出力範囲
シグモイド関数は0から1の間の値を出力します。この特性が、確率的な解釈を容易にし、特に出力層での利用を促しています。しかし、この出力範囲が勾配消失問題を引き起こす要因ともなっています。
ReLU関数の出力範囲
ReLU関数は0以上の実数を出力します。この無限の出力範囲が、特定の状況下での学習を加速する要因となっていますが、一方でニューロンの「死」や負の値の不扱いなどの問題も引き起こします。
主な違い2:勾配消失問題

ディープラーニングの学習プロセスにおいて、勾配消失は避けるべき重要な課題となります。特に深いニューラルネットワークでは、この問題が学習の速度や精度に大きな影響を与えることが知られています。
シグモイド関数と勾配消失問題
前述のように、シグモイド関数の出力範囲が0から1のため、この関数の微分値は最大で0.25となります。したがって、ネットワークが深くなると、勾配は指数関数的に小さくなってしまい、更新がほとんど行われなくなる「勾配消失」が生じます。
ReLU関数と勾配消失問題
ReLU関数は負の入力値に対しては0を出力するため、その部分の勾配は0となります。しかし、正の入力に対しては勾配は1であり、これにより勾配消失問題は大幅に緩和されます。しかし、一部のニューロンが学習中に更新されなくなる「死亡ReLU」という別の問題が生じることがあります。
シグモイド関数とReLU関数は、それぞれ独特の特性や課題を持っています。これらの違いを理解することで、最適な活性化関数の選択やディープラーニングのモデル設計がより適切に行えるようになります。
主な違い3:計算速度

活性化関数の選択は、学習の効率や実行速度にも影響を与える要因となります。特に大規模なモデルやリアルタイムのアプリケーションでは、計算速度は極めて重要です。
シグモイド関数の計算速度
シグモイド関数は、指数関数を含む形式のため、計算には比較的時間がかかる場合があります。しかし、モダンなディープラーニングフレームワークでは効率的な実装がなされており、日常的な使用においては大きな問題とはならないことが多いです。
ReLU関数の計算速度
ReLU関数はシンプルな形状を持っているため、計算は非常に高速です。これは、ディープラーニングの学習や推論時において大きなアドバンテージとなります。
適用シナリオ:どちらの関数を使用するべきか?

シグモイド関数とReLU関数、どちらを選択すべきかは、使用シナリオによって異なります。以下に、いくつかの一般的なガイドラインを示します。
二値分類の出力層
シグモイド関数の出力範囲が0から1のため、二値分類の出力層に適しています。確率としての解釈が直感的であり、実際の多くのモデルで使用されています。
深いネットワークの隠れ層
ReLU関数は、勾配消失問題を緩和し、計算速度も速いため、深いネットワークの隠れ層には特に適しています。しかし、「死亡ReLU」問題に注意する必要があります。
チューニングと実験
最終的には、特定のタスクやデータセットに最も適した活性化関数を見つけるためには、実験とチューニングが不可欠です。様々な関数やそのバリエーションを試すことで、最適なモデルを見つけることができます。
活性化関数の選択は、モデルの性能や学習の効率を大きく左右する要因となります。シグモイド関数とReLU関数の特性や違いを理解し、それぞれのシナリオに合わせて適切に選択することが、成功への鍵となります。
その他の活性化関数

シグモイド関数とReLU関数以外にも、ディープラーニングにおいて利用される様々な活性化関数が存在します。ここでは、その中からいくつか代表的なものを紹介します。
ハイパボリックタンジェント (tanh)
tanh関数は、シグモイド関数の一種とも言える関数で、出力範囲が-1から1です。これにより、中心が0となるため、シグモイド関数よりも学習が安定することが多いです。
Leaky ReLU
ReLU関数の「死亡」問題を緩和するためのバリエーション。負の入力値に対しても微小な勾配を持つため、ニューロンの「死」を回避することができます。
Parametric ReLU (PReLU)
Leaky ReLUの拡張版で、負の部分の勾配も学習することができます。
Softmax関数
多クラス分類タスクの出力層でよく使用される関数。各クラスの確率としての出力を生成します。
最適な活性化関数の選び方

活性化関数を選択する際には、いくつかの要因を考慮する必要があります。
タスクの性質
二値分類や多クラス分類、回帰など、タスクの性質に応じて最適な活性化関数が異なります。
ネットワークの深さ
深いネットワークを使用する場合、勾配消失や勾配爆発を回避するための活性化関数を選ぶことが重要です。
実験の重要性
理論やガイドラインに基づく選択は基本ですが、最終的には実際のデータセットやタスクにおける実験が最も信頼性のある方法です。様々な活性化関数を試して、性能を評価することで、最適な選択を行えます。
活性化関数は、ニューラルネットワークの性能を大きく左右する要素の一つです。ディープラーニングのモデル設計やチューニングにおいて、これらの関数の特性や違いを十分に理解し、最適な選択を行うことが求められます。
まとめ:ReLU関数とシグモイド関数の使い分け

この記事を通して、ReLU関数とシグモイド関数の基本的な特性や主な違い、さらにはその他の活性化関数との関係について学びました。これらの活性化関数は、ディープラーニングのモデル設計において重要な役割を果たします。それぞれの関数の選択は、特定のタスクやモデルの要件に基づいて行われるべきです。
- シグモイド関数:出力が0から1の範囲であり、二値分類の出力層や、確率を示す場面での使用が適しています。
- ReLU関数:計算速度が速く、勾配消失問題を緩和する特性から、深いネットワークの隠れ層に特に推奨されます。しかし、”死亡ReLU”問題に注意が必要です。
最終的には、シグモイド関数、ReLU関数、またはその他の活性化関数の中から、特定の問題やデータセットに最も適したものを選択する必要があります。最適な選択を行うためには、理論的な背景やガイドラインだけでなく、実際の実験や評価を行うことが不可欠です。
活性化関数の選択は、ニューラルネットワークの性能や学習の効率を大きく左右します。シグモイド関数とReLU関数の特性や違いを十分に理解し、実践的な場面で適切に選択する能力を磨くことが、ディープラーニングの成功への鍵となります。