
人間が世界から情報を吸収するとき、私たちは本能的に多くの感覚を使用します。たとえば、賑やかな通りを見るとき、車のエンジンの音も同時に聞きます。今日、我々はそのような人間の能力に一歩近づく新しいアプローチを紹介します。
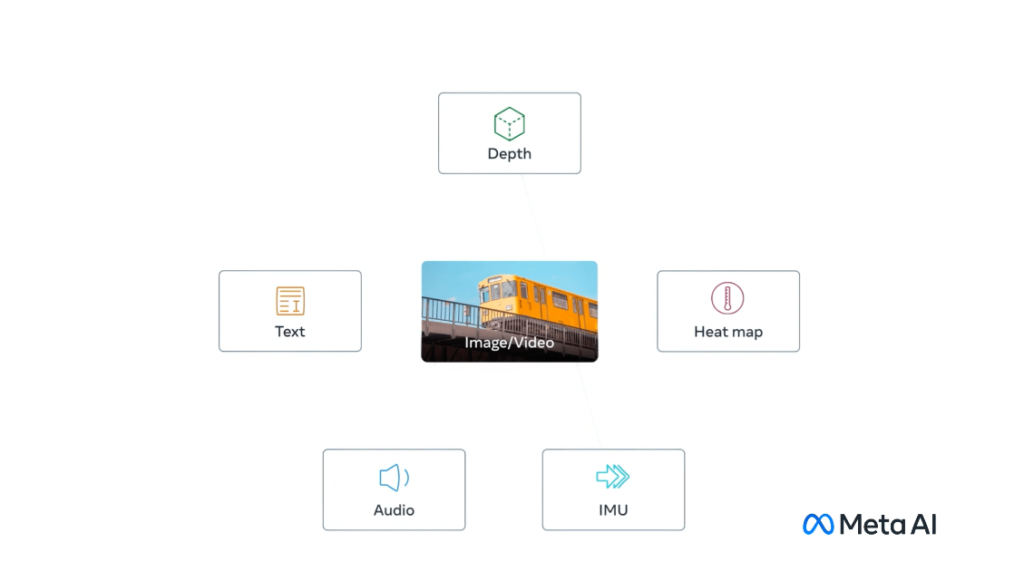
それは、AIが複数の情報形式から同時に、全体的に、そして直接学習する能力です。この記事では、Metaが開発しオープンソース化した最初のAIモデル、ImageBindについて詳しく解説します。このモデルは、テキスト、画像/ビデオ、オーディオだけでなく、深度(3D)、熱(赤外線放射)、そして運動と位置を計算する慣性計測装置(IMU)といったセンサーからの情報を結びつけることができます。
ImageBindとは?: 6つのモダリティを統合するAIモデル
出典:Meta AI
ImageBindは、6つの異なるモダリティから情報を結びつけることが可能なAIモデルで、単一の埋め込み空間、つまり共有された表現空間を学習します。これにより、マシンは写真の中の物体を、その音、3D形状、温度、そして動きと関連付けることで、物事を全体的に理解する能力を備えることができます。
ImageBindは、個々のモダリティについて個別に訓練された専門的なモデルを上回る性能を発揮し、Metaの「Make-A-Scene」のようなツールが、例えば熱帯雨林や市場の音に基づいて画像を生成することを可能にします。その他の将来的な可能性としては、より正確な認識やコンテンツの接続、モデレーション、そして創造的なデザインの強化が挙げられます。
これらの機能は、ImageBindがすべての可能なデータタイプから学習する多様なAIシステムを作り出すMetaの取り組みの一部であり、モダリティの数が増えるにつれて、ImageBindは研究者たちが新しい、全体的なシステムを開発するための可能性を開拓しています。
例えば、3DやIMUセンサーを組み合わせて没入型のバーチャルワールドをデザインしたり体験したりするシステムが考えられます。また、ImageBindは、テキスト、オーディオ、画像の組み合わせを使って写真、ビデオ、オーディオファイル、テキストメッセージを探す新たな方法を提供することも可能です。
一般的なAIシステムでは、各モダリティに対して特定の埋め込み(つまり、機械学習でデータとその関係を表現できる数値のベクトル)が存在します。しかし、ImageBindは、全てのモダリティの組み合わせでデータを訓練することなく、複数のモダリティ間で共有の埋め込み空間を作り出すことが可能であることを示しています。これは重要なポイントであり、例えば、都市の騒音と温度データ、または海辺の断崖とそのテキストの説明といった組み合わせを含むデータサンプルを作成することは現実的には困難だからです。
以上が、ImageBindという画期的なAIモデルの基本的な概要です。次のセクションでは、このモデルの具体的な特徴と、どのようにしてホリスティックな学習とモダリティ間の結びつきを実現しているのかを詳しく見ていきましょう。
ImageBindが目指す「一つの埋め込み空間」の学習

私たち人間は、一つの説明を読むだけで新しい概念を理解したり、見たことのない車のモデルの写真を見てエンジン音を予想したりする能力を持っています。これは、一つの画像が実際には全体的な感覚体験を「結びつける」能力があるからです。
しかし、AIの分野では、モダリティが増えると、ペアになっていないデータに依存する標準的なマルチモーダル学習が制約となります。理想的には、多種多様なデータが分布する一つの共有埋め込み空間があれば、モデルは視覚的な特徴と他のモダリティを一緒に学習することが可能になります。
以前は、全てのモダリティに対してこのような共有埋め込み空間を学習するには、全ての可能な組み合わせのペアデータを集める必要がありましたが、これは非現実的な挑戦でした。しかし、ImageBindはこの課題を、大規模な視覚-言語モデルを活用し、ビデオ-オーディオや画像-深度データなど、画像と自然にペアリングする新しいモダリティにゼロショット能力を拡張することで解決しました。
▼関連記事▼
ゼロショット学習徹底解説: 基本原理から応用分野・評価指標・将来展望まで
ImageBindによる6つのモダリティの結びつけ
出典:Meta AI
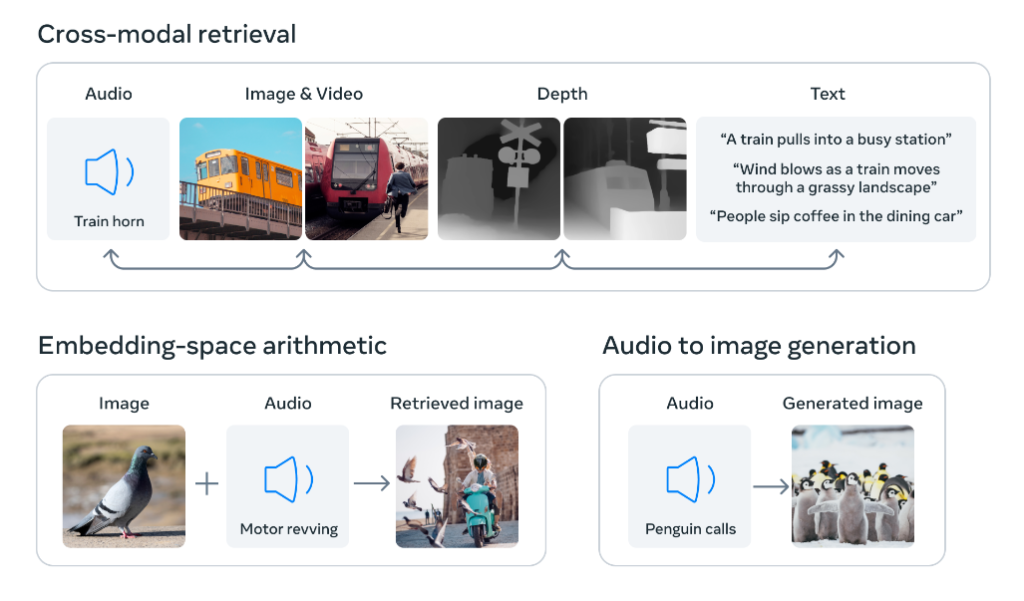
大規模なウェブデータから学んだ視覚的な表現は、異なるモダリティの特徴を学習する目標として使用できます。これにより、ImageBindは画像と共起する任意のモダリティを自然に整列し、それらのモダリティを自然に整列させることができます。例えば、画像と強く相関するモダリティ(熱や深度など)は整列しやすく、視覚的ではないモダリティ(音声やIMUなど)は相関が弱いです。
ImageBindは、6つのモダリティを結びつけるために画像ペアデータが十分であることを示しています。このモデルは、内容をより全体的に解釈することができ、なるモダリティが互いに「対話」し、それらが一緒に観察されなくてもリンクを見つけることが可能です。
例えば、ImageBindは音声とテキストを一緒に見ることなく関連付けることができます。これにより、他のモデルがリソース集約的な訓練なしで新しいモダリティを「理解」することが可能になります。ImageBindの強力なスケーリング挙動は、他のモダリティを使用することを可能にすることで、多くのAIモデルを代替または強化することができます。
たとえば、Make-A-Sceneはテキストプロンプトを使用して画像を生成することができますが、ImageBindはそれをアップグレードして、笑い声や雨の音などの音声を使用して画像を生成することができます。
▼関連記事▼
プロンプトエンジニアとは?ジェネレーティブAIを使い倒すための徹底解説【ChatGPT】
さらに、自己教師付きの学習を用いたImageBindは、非常に少ない訓練例を使用することでモデルの性能を実際に向上させることができます。新たなスケーリング挙動、つまり小さいモデルには存在しなかったが大きなバージョンに現れる能力が生まれます。これには、ある画像にどの音声が適しているかを認識することや、写真からシーンの深さを予測することが含まれます。
▼関連記事▼
教師あり学習と教師なし学習の違いを徹底解説!選択基準・代表的アルゴリズム・業界別事例まで完全ガイド
ImageBindが生み出す新たな可能性

多モーダルな入力クエリの使用と他のモーダルでの出力取得という能力を持つImageBindは、クリエイターたちに新たな可能性を示します。例えば、海の夕日のビデオ録画を取り、それを強化するための完璧な音声クリップを瞬時に追加できるでしょう。
また、ブリンドルのシーズー犬の画像が、同じ犬種のエッセイや深度モデルを生成する可能性があります。Make-A-Videoのようなモデルがカーニバルのビデオを制作したとき、ImageBindはそれに伴う背景ノイズを提案し、没入感のある体験を作り出すことができると思われます。
音声に基づいて画像の中のオブジェクトをセグメント化し、識別することさえ可能です。これは、音声プロンプトと組み合わせて静止画像からアニメーションを作り出す独特の機会を生み出します。
例えば、クリエーターはイメージとアラーム時計やコケコッコーと組み合わせ、コケコッコーの音声プロンプトを使ってニワトリをセグメント化したり、アラームの音で時計をセグメント化して、それらをビデオシーケンスにアニメーション化することができます。
ImageBindの使い方:GitHubでオープンソースへアクセス
ImageBindはオープンソースかされており、GitHubにて公開されています。使い方のガイドが記載されていますので、詳細はGitHubをご参照下さい。
出典:GitHub
マルチモーダル学習の未来

現在の研究では6つのモダリティを探究していますが、可能な限り多くの感覚を結びつける新たなモダリティの導入、例えば、タッチ、スピーチ、匂い、脳のfMRI信号などが、より豊かな人間中心のAIモデルを可能にすると考えられます。
マルチモーダル学習についてはまだ解明すべきことがたくさんあります。AI研究コミュニティは、大きなモデルにのみ現れるスケーリング行動を効果的に量化し、その応用を理解することがまだありません。ImageBindは、これらを厳密に評価する一歩であり、画像生成や取得の新たな応用を示すかもしれません。
様々な研究コミュニティがImageBindとそれに伴う公開論文を探求し、ビジョンモデルを評価する新たな方法を見つけ、新たな応用を生み出すことを期待しています。特に、既存のAIモデルの能力を強化し、それらが他のモダリティを使用できるようにするというImageBindの能力は、AI開発者にとって興味深い可能性を提供するでしょう。
これらの取り組みを通じて、AIは人間が情報を理解する方法に近づいていくでしょう。そしてImageBindは、その進化の一部であり、人間が情報を統合的に理解する能力を模倣することで、AIが新たな形で情報を解析し、世界との関わり方を改善するのを助けます。
まとめ
ImageBindは、AIの多モーダル学習における画期的なステップと言えます。テキスト、画像/ビデオ、オーディオだけでなく、深度(3D)、熱(赤外線放射)、慣性測定装置(IMU)といったセンサーからの情報も一つに結びつけることが可能で、AIは人間のように情報を全体的に理解する能力を持つようになります。
また、それは既存のAIモデルの能力を強化し、他のモダリティを使用できるようにすることで、AI開発者にとって新たな可能性を提供します。人間が情報を理解する方法に近づくAIの進化の一部として、ImageBindは情報解析の新しい形を生み出し、AIが世界との関わり方を改善するのを助けます。このような技術の進展は、我々の生活をより豊かで繋がりのあるものに変えていくでしょう。