生成AIやAIエージェントの活用が本格化した今、データサイロは単なるIT課題ではなく、企業の競争力そのものを左右する経営テーマになっています。部門ごとに分断されたデータ、乱立する特化型AI、老朽化したレガシーシステム。これらが重なり合い、意思決定の遅れや誤作動という深刻なリスクを生み出しています。
特に2026年は、AI導入の「実験フェーズ」が終わり、投資対効果やガバナンスが厳しく問われる転換点です。AIエージェントが自律的に業務を実行する時代において、データは人間のためだけでなく、機械が正しく理解し行動するための基盤であることが求められています。
本記事では、AIサイロという新たな脅威、MDMやセマンティックレイヤーの再評価、データメッシュとデータファブリックの融合、日本企業が直面する2025年の崖の現実、そしてROIを生み出す具体的な方向性までを整理します。最新の事例や数値を交えながら、これからのデータ統合戦略を俯瞰的に理解できる内容です。
2026年にデータサイロが経営課題へと変貌した理由
2026年にデータサイロが経営課題へと格上げされた最大の理由は、生成AI、とりわけ自律型AIエージェントが意思決定と業務執行の中枢に入り込んだことにあります。従来、データサイロは「部門間の非効率」や「分析スピードの遅さ」として語られてきましたが、AIが主体的に行動する時代では、その影響範囲が経営リスクそのものに直結します。
Forresterの2026年予測によれば、企業向けソフトウェアは人間中心のUI設計から、プロセスとデジタルワーカー中心の設計へ移行しています。AIエージェントはERP、CRM、サプライチェーンなど複数システムを横断し、API経由でデータを取得・判断・実行します。このとき、データが部門ごとに分断され、定義や粒度が異なっていれば、AIは人間のように空気を読んで補完できません。
結果として、在庫数や売上指標の定義差異が、誤発注や誤った価格調整といった自動化された誤判断を引き起こします。IDCは、AIエージェント活用の拡大により、企業内のAPIトラフィックが2027年までに1,000倍規模になると予測しており、これはサイロ化したデータが誤りを増幅させる構造的条件が整ったことを意味します。
| 観点 | 従来(〜2020年代前半) | 2026年以降 |
|---|---|---|
| 主な利用者 | 人間(分析・参照) | AIエージェント(実行) |
| サイロの影響 | 非効率・手戻り | 経営判断の誤作動 |
| 問題の性質 | IT課題 | 経営・ガバナンス課題 |
さらに2026年には、領域特化型AIの普及による「AIサイロ」が顕在化しました。マーケティングAIと財務AIが同じ「売上」という言葉を異なる意味で解釈する状況は、組織としての共通認識の崩壊を招きます。ガートナーが指摘するように、生成AIのROIを左右する最大要因はデータの一貫性とガバナンスであり、技術性能そのものではありません。
このように、データサイロは単なるIT構造の問題ではなく、AI時代の経営における前提条件を破壊する要因へと変貌しました。データがつながっていない企業は、AIを導入しても競争優位を築けず、むしろ自動化されたリスクを抱え込むことになります。2026年においてデータサイロが経営課題と位置づけられるのは、極めて必然的な帰結なのです。
AIエージェント時代に顕在化する新たな「AIサイロ」問題
AIエージェントの本格活用が進む2026年において、従来とは質的に異なる「AIサイロ」問題が顕在化しています。これは部門ごとにデータが分断される従来型のサイロとは異なり、特定業務に最適化されたAI同士が、組織内で共通理解を持てずに孤立する現象を指します。生成AIの高度化が進む一方で、企業の知能が逆に分断されるという逆説的な状況が生まれています。
背景にあるのは、汎用LLMから領域特化型AIへの急速なシフトです。ForresterやIDCが指摘するように、2026年は「汎用AIの限界」が明確になり、製造、財務、医療、マーケティングなど、それぞれの専門知識を学習したDSLMの導入が加速しています。これらは単体では高精度ですが、学習データや前提定義が異なるため、同じ言葉でも意味が一致しないという問題を孕みます。
| 観点 | 従来のデータサイロ | AIサイロ |
|---|---|---|
| 主因 | 部門・システム分断 | 特化型AIの乱立 |
| 問題の表出 | 分析や可視化の遅延 | 自律処理の誤作動 |
| 影響範囲 | 人間の意思決定 | AIエージェント間連携 |
例えば「売上」という基本指標一つでも、マーケティングAIは受注ベース、財務AIは入金ベースで解釈する可能性があります。人間であれば会話で調整できますが、高速で動作する自律型エージェント間では、このズレが即座に誤った発注や請求処理につながります。Gartnerは、生成AIのハルシネーション対策コストが想定以上に膨らむ要因として、こうした定義不一致を挙げています。
さらに深刻なのは、AIサイロが可視化されにくい点です。システム障害のように明確なエラーが出るのではなく、一見もっともらしい判断が静かに積み重なり、経営判断や顧客体験を歪めていきます。これは単なるIT課題ではなく、組織の知的整合性そのものの問題です。
このようにAIエージェント時代のサイロ問題は、データの置き場所ではなく「意味」と「前提」の分断として現れます。AIを増やすほど賢くなるはずの組織が、実は内側から分裂していく。この構造的リスクを正しく理解することが、次の一手を誤らないための前提条件になっています。
共通言語として再評価されるマスターデータ管理(MDM)の役割
AIエージェントが業務の主体となり始めた2026年において、組織内で再び注目を集めているのがマスターデータ管理です。かつてMDMは、住所や商品コードを揃えるための地味な基盤整備と捉えられがちでした。しかし現在では、**複数のAIエージェントが同じ意味を共有し、誤解なく連携するための共通言語**として、その価値が根本から見直されています。
ForresterやGartnerの分析によれば、AI活用が本格化するほど、データの定義不整合が業務リスクに直結する割合が高まるとされています。人間であれば会話や経験で補正できた曖昧さも、AIエージェントにとっては致命的です。MDMはこの問題に対し、顧客、製品、取引先といった基幹エンティティに一意の識別子と正規化された属性定義を与え、AIが参照すべき唯一の正解を提供します。
| 観点 | MDM未整備の場合 | MDM整備後 |
|---|---|---|
| 売上の解釈 | 部門・AIごとに定義が異なる | 全AIが同一定義を参照 |
| 顧客識別 | 表記揺れ・重複が多発 | Golden IDで一元管理 |
| 自動処理の信頼性 | 誤判断・誤作動が発生 | ルールに基づき安定動作 |
特に重要なのは、MDMが単なるデータ格納庫ではなく、**ガバナンスを内包した信頼の源泉**として機能する点です。どのAIエージェントも、意思決定やトランザクション実行の前にMDMを参照するという前提を設けることで、組織全体の自律動作に秩序が生まれます。これは、人間社会における法令や社内規程に近い役割だと言えます。
実際、グローバル企業や日本の先進事例では、MDMをセマンティックレイヤーと連動させ、API経由でAIエージェントに常時提供しています。Gartnerが示す2026年のデータマネジメント潮流でも、MDMはAIガバナンスの中核コンポーネントとして位置付けられています。**MDMを欠いたAI導入は、短期的にはスピードが出ても、長期的には制御不能なAIサイロを生み出す**という評価が定着しつつあります。
このようにMDMは、効率化のための裏方から、AI時代の協調知能を支える言語基盤へと進化しました。共通言語を持たない組織に、マルチエージェントの知性は根付かないという現実が、2026年の企業経営に重く突きつけられています。
データメッシュとデータファブリックはなぜ融合に向かったのか
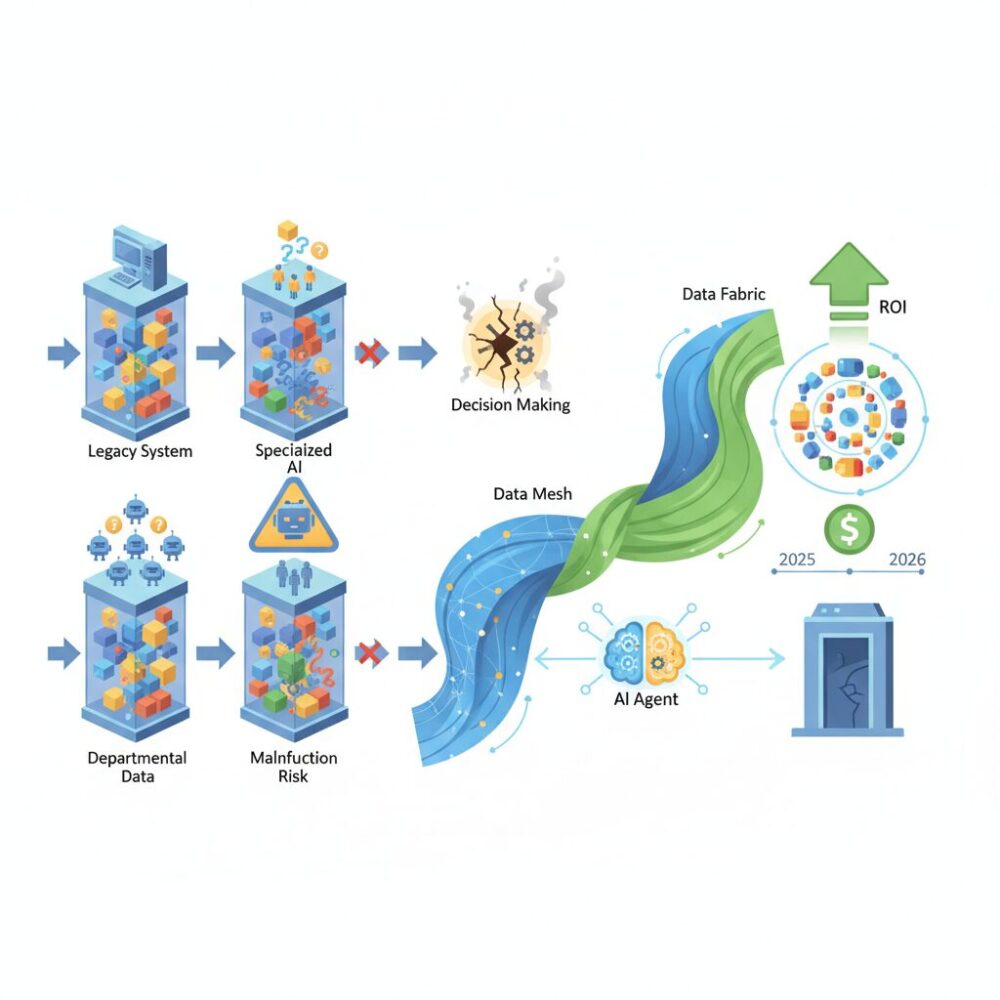
データメッシュとデータファブリックが融合に向かった最大の理由は、AIエージェントが企業活動の前提条件になったことで、従来の「中央集権か分散か」という二項対立が現実に耐えなくなった点にあります。かつては、全社最適を重視するなら中央集権型、現場のスピードを優先するなら分散型という選択が成立していました。しかし2026年現在、そのどちらか一方では、AIが横断的に動く業務要件を満たせなくなっています。
ForresterやGartnerの分析によれば、AIエージェントは複数システム・複数部門のデータを前提に自律的な判断と実行を行うため、「意味の統一」と「即時アクセス」を同時に満たすデータ基盤が不可欠だとされています。中央集権型のデータファブリックはアクセス性と統制に優れる一方、業務文脈の反映が遅れがちです。逆にデータメッシュは文脈理解に強いものの、技術や運用が分散しすぎるとAI連携の前提となる一貫性を失います。
| 観点 | 単独アプローチの限界 | 融合後に得られた効果 |
|---|---|---|
| 意味定義 | 部門ごとに解釈が分断 | セマンティックレイヤーで共通化 |
| スピード | 中央ITがボトルネック化 | ドメイン主導で即時改善 |
| 統制 | 分散環境でガバナンス崩壊 | ポリシーは中央で一元管理 |
実務的な転換点となったのが、AIサイロの顕在化です。領域特化型AIが増えるにつれ、同じデータ項目でもAIごとに異なる解釈が生じ、誤った自動処理が連鎖する事例が報告されました。IDCが指摘するように、APIコールやデータ参照が爆発的に増える環境では、人手による調整を前提としたガバナンスは機能しません。この問題に対し、中央で意味とルールを定義しつつ、データ生成と品質責任はドメインに委ねるという融合モデルが、最も現実的な解となりました。
さらに、日本企業特有の背景も融合を後押ししています。レガシーシステムが残る企業では、全社一括刷新が困難である一方、現場主導のデータ活用だけでは全体最適に至りません。データファブリックが既存資産を包摂する共通基盤となり、その上でデータメッシュの思想を適用することで、段階的にAI対応型のデータ構造へ移行できることが実証されてきました。
結果として、融合は思想的な妥協ではなく、AI時代の必然的な進化と位置づけられています。中央と分散の役割を明確に切り分け、意味と接続性を機械可読な形で共有する。この構造こそが、AIエージェントが安全かつ高速に価値を生み出すための土台となり、データメッシュとデータファブリックを再定義した最大の理由なのです。
セマンティックレイヤーがもたらす意味共有とAIの安全性
セマンティックレイヤーが注目される最大の理由は、AIエージェント同士が安全に意味を共有するための基盤として機能する点にあります。2026年現在、AIのリスクはモデル性能そのものよりも、誤った意味解釈が自律的な処理を通じて連鎖することにあります。Forresterが指摘するように、企業AIの事故の多くはアルゴリズムではなくデータ定義の不整合に起因しています。
セマンティックレイヤーは、売上、顧客、在庫、粗利益といったビジネス用語を単なる人間向けの説明ではなく、機械が解釈可能な形で定義します。これにより、AIエージェントは各システムの生データを直接解釈するのではなく、必ず意味が正規化されたAPIやビューを介して判断を行います。この仕組みが、ハルシネーションの実害化を防ぐ第一の防波堤になります。
特にマルチエージェント環境では、意味のズレは致命的です。例えば在庫補充を担うAIと財務AIが異なる「在庫評価額」の定義を持っていた場合、発注と会計処理が矛盾したまま自動実行されます。Gartnerの生成AIガイドでも、こうした自動化エラーは人手による事後検知が困難で、ガバナンスレイヤーでの予防が不可欠だと強調されています。
| 観点 | セマンティックレイヤーなし | セマンティックレイヤーあり |
|---|---|---|
| 用語定義 | 部門・AIごとにバラバラ | 中央で一元管理 |
| AI判断の一貫性 | 低く、結果が衝突 | 高く、再現性あり |
| 安全性 | 誤処理が連鎖 | 定義違反を事前遮断 |
また、セマンティックレイヤーはAIセーフティの観点から説明責任を担保する装置でもあります。AIがどのKPI定義、どの計算ロジックに基づいて結論を出したのかを遡れるため、監査や内部統制に耐えうる判断プロセスを構築できます。これは金融、製造、公共分野など規制産業で特に重要視されています。
さらに、RAGやDSLMと組み合わせることで、セマンティックレイヤーはAIに与えるコンテキストの品質を大きく引き上げます。曖昧な自然言語のまま検索させるのではなく、意味が固定された概念IDを通じて検索・生成を行わせることで、情報漏洩や誤引用のリスクも低減します。
結果としてセマンティックレイヤーは、単なる分析効率化のための仕組みではなく、AIが組織の中で暴走せず、信頼できる判断主体として機能するための安全基盤になります。AIエージェント時代における競争力は、モデルの賢さではなく、意味をどれだけ厳密に共有できているかで決まる段階に入っています。
RAG実運用で浮上したベクトルデータベースのサイロ化
RAGの実運用が本格化した2026年、多くの企業で新たなデータサイロとして顕在化しているのが、ベクトルデータベースのサイロ化です。PoC段階では迅速さが重視され、部門やプロジェクト単位で独立したベクトルDBが構築されましたが、その構成が本番環境に持ち込まれた結果、統制不能な状態に陥るケースが増えています。**これは従来のデータサイロとは異なり、AIの回答品質とガバナンスを同時に劣化させる点で、より深刻な問題です。**
最大の問題は、ベクトル化されたデータが元データのライフサイクルから切り離されやすい点にあります。文書が更新・廃止されてもEmbeddingが再生成されず、AIは古い情報を「それらしく」回答してしまいます。Forresterが2026年の生成AI予測で指摘している通り、RAGにおける信頼性低下の主因はモデル性能ではなく、検索対象データの鮮度と来歴管理にあります。人間向けナレッジ管理では許容されていた曖昧さが、AIエージェント時代には業務事故へ直結します。
加えて見過ごされがちなのが、権限とコンプライアンスの断絶です。元文書では厳密なアクセス制御が行われていても、ベクトルDB側にそのメタデータが継承されない場合、AI経由で機密情報が横断的に参照可能になります。Gartnerも、2025年以降に発生した生成AI関連インシデントの多くが「検索層のガバナンス欠如」に起因すると分析しています。
| 観点 | PoC段階 | 実運用での影響 |
|---|---|---|
| 更新管理 | 手動・不定期 | 情報陳腐化による誤回答 |
| 権限継承 | 考慮外 | 情報漏えいリスク |
| 可観測性 | ログ最小限 | 原因特定不能 |
先進企業では、この問題を単なるDB整理ではなく運用設計の問題として捉えています。具体的には、データリネージと可観測性を備えた自動Embeddingパイプラインを構築し、元データの更新をトリガーに再ベクトル化を行う仕組みへ移行しています。DatabricksやSnowflakeの技術者コミュニティでも、VectorOpsやLLMOpsという概念が定着しつつあり、RAGは一過性の実装ではなく継続運用するプロダクトだという認識が共有されています。
重要なのは、ベクトルDBを「高速検索用の裏方」と見なさないことです。**そこには意思決定に影響する意味情報が蓄積されており、MDMやセマンティックレイヤーと同等の統制対象です。**RAG実運用で浮上したこのサイロ問題は、AI活用の成否を分ける分水嶺として、経営レベルでの理解と対策が求められています。
2025年の崖を越えた日本企業と越えられない企業の差
2025年の崖を越えた日本企業と、越えられなかった企業の差は、2026年時点で明確に可視化されています。その本質的な違いは、IT刷新の有無ではなく、データとAIを経営資源として再定義できたかどうかにあります。経済産業省のDXレポートが示した年間最大12兆円の損失予測は、2025年に一度きりの危機として終わったのではなく、競争力の差として現在進行形で企業価値を分けています。
崖を越えた企業に共通するのは、レガシーシステムを即座に全廃する現実離れした選択ではなく、データを軸にした段階的なモダナイゼーションを進めてきた点です。iPaaSやAPI連携を用いて既存資産を生かしつつ、MDMやセマンティックレイヤーを整備し、AIエージェントが安全に利用できるデータ基盤を構築しました。Forresterが指摘するように、2026年はAI導入の再評価期であり、価値を生まないPoCを整理し、実業務に組み込めた企業だけが成果を出しています。
一方、崖を越えられなかった企業では、IT予算の約8割が依然として保守運用に固定され、新規投資に回せる余力がありません。人材面でも、ブラックボックス化した基幹システムを扱える人材が高齢化し、軽微な改修でも経営判断レベルのコストと時間を要しています。最大の問題は、AIを使いたくても、データがサイロ化しており使えない状態が常態化している点です。
| 観点 | 崖を越えた企業 | 越えられない企業 |
|---|---|---|
| データ戦略 | MDMと意味定義を整備し全社共通化 | 部門最適のままデータが分断 |
| AI活用 | AIエージェントを業務プロセスに実装 | チャットボット止まり、または未導入 |
| IT投資構造 | 攻めの投資比率を段階的に拡大 | 保守運用費が大半を占有 |
象徴的な差は、意思決定スピードにも表れています。データが統合された企業では、需要予測や在庫判断、顧客対応をAIエージェントが自律的に支援し、経営層は結果を前提に戦略判断へ集中できます。Gartnerが示す新たなROI概念であるROFの観点では、新技術を即座に取り込める柔軟性そのものが競争優位となっています。
2025年の崖を越えたか否かは、もはや過去の評価ではありません。2026年現在、その差は売上成長率、付加価値創出力、人材定着率といった複数の指標に波及しています。崖を越えられなかった企業に残された時間は限られていますが、データを共通言語として再設計する決断さえできれば、完全な脱落を避ける余地はまだ残されています。
iPaaSとデータ連携ツールの最新動向と選定ポイント
2026年現在、iPaaSとデータ連携ツールは単なるシステム接続基盤ではなく、AIエージェント時代の業務自律化を支える中核インフラへと進化しています。ForresterやGartnerの分析によれば、企業内で稼働するAIエージェント数とAPIトラフィックは指数関数的に増加しており、連携基盤の設計次第でAI活用の成否が分かれる局面に入っています。
特に顕著なのが、可観測性とインテリジェンスを内包したiPaaSへのシフトです。従来はデータが流れているかどうかを事後的に確認する運用が一般的でしたが、2026年の主流はリアルタイムでの障害検知や遅延分析、さらにはAIによる異常予測です。これはSREの考え方がデータ連携領域にも本格的に持ち込まれた結果であり、IDCが示すように大規模企業では連携障害による業務停止コストが年間数十億円規模に達することも背景にあります。
一方、日本市場ではノーコード・ローコード型iPaaSの存在感がさらに高まっています。BizteX ConnectやYoom、JENKAなどは、日本特有の業務フローやSaaS連携に最適化され、非エンジニア主導でのデータ統合を可能にしています。ITreviewのユーザーレビュー分析でも、導入後6か月以内に業務自動化の効果を実感した企業が多数を占め、データメッシュ型組織との親和性が評価されています。
加えて、生成AIアダプターの標準装備は2026年の大きな転換点です。ASTERIA Warpをはじめとする実績あるツールでは、生成AIを連携フローの一部として組み込み、非構造化データの解釈や名寄せ、メタデータ付与を自動化しています。これにより、従来は人手に依存していたデータクレンジング工程が大幅に短縮され、AI自身がデータ品質向上に寄与する循環が生まれています。
| 観点 | 従来型連携 | 2026年型iPaaS |
|---|---|---|
| 主目的 | システム接続 | AI前提の業務自律化 |
| 運用管理 | 事後監視 | 可観測性と予測 |
| データ処理 | 定型変換 | 生成AIによる解釈・補正 |
こうした状況を踏まえたツール選定では、価格やコネクタ数だけで判断するのは危険です。Gartnerが指摘するように、今後の評価軸はAIエージェントとの親和性、メタデータ管理やMDMとの統合可能性、そしてガバナンス適用の柔軟性に移っています。特に、セマンティックレイヤーやRAG基盤と連動できるかどうかは、中長期の拡張性を左右します。
重要なのは、iPaaSを単独のツールとして導入するのではなく、統合データ基盤全体の設計思想の中で位置づけることです。経済産業省やデジタル庁が進める標準化の流れを見ても、オープンなAPIと疎結合な連携は今後さらに求められます。iPaaSの選定は、目先の効率化ではなく、AIエージェントが安全かつ正確に動き続けるための基盤投資として捉える視点が不可欠です。
セキュリティ・ガバナンスとデータ主権の新しい考え方
2026年のデータ活用において、セキュリティとガバナンスは「守りの制約」ではなく、分散環境で価値を最大化するための設計思想として再定義されています。AIエージェントが複数のクラウドやデータ基盤を横断的に利用する現在、従来の境界型セキュリティや部門単位の統制では、リスクと非効率の両方を拡大させてしまいます。
特に注目されているのが、オープンテーブルフォーマットの普及に伴うガバナンスの再設計です。Apache IcebergやDelta Lakeにより、データ自体はプラットフォーム非依存で扱えるようになりましたが、アクセス制御やマスキングといったポリシーが各基盤に分断されるという新たな課題が顕在化しました。Gartnerの分析によれば、こうしたポリシー分断は内部不正や意図せぬ情報漏えいの主要因になりつつあるとされています。
| 観点 | 従来型ガバナンス | 2026年型ガバナンス |
|---|---|---|
| 管理単位 | システム・部門ごと | ポリシー中心 |
| 適用方法 | 静的な権限設定 | コンテキストに応じた動的制御 |
| AI対応 | 想定外 | AIエージェント前提 |
この流れの中で主流になりつつあるのが、ポリシー・メタデータ駆動型の中央ガバナンスです。物理的なデータは分散したまま、誰が、どの目的で、どの粒度までアクセスできるのかを、単一のポリシーエンジンで判断します。ユーザー属性、業務目的、時間帯、AIか人間かといった文脈情報を組み合わせ、クエリレベルで自動的にマスキングや制限を行う仕組みは、Forresterが提唱する「Adaptive Trust」の考え方とも一致します。
もう一つの重要な軸がデータ主権です。日本ではデジタル庁が推進するエリアデータ連携基盤を通じ、データの所有と利用を分離する発想が社会実装段階に入りました。個人や企業がデータの主導権を保持したまま、APIを介して必要最小限のデータのみを共有するモデルは、巨大プラットフォームへの一極集中とは異なる選択肢を示しています。
災害時に限定的な医療情報を共有するユースケースが象徴するように、データ主権は「共有しない権利」ではなく、安心して共有できる条件を定義することに本質があります。企業にとってもこれは同じで、取引先や自治体、業界横断のデータ連携を進める上で、主権とガバナンスを明確に設計しているかどうかが、AI時代の信頼資本そのものになりつつあります。
分散しているからこそ、統制は知的でなければならない。これが2026年におけるセキュリティ・ガバナンスとデータ主権の新しい考え方です。
コスト削減を超えるROIと価値創出の実例
データサイロ解消や統合データ基盤への投資は、長らくコスト削減効果だけで評価されがちでしたが、2026年現在、そのROIは明確に価値創出型へと進化しています。特にAIエージェントが業務の意思決定や実行に深く関与するようになったことで、データ統合は新たな収益機会や競争優位を生み出す源泉として再定義されています。
象徴的な事例が、JDMCのデータマネジメント賞で大賞を受賞した関西電力です。同社は全社的なデータガバナンスと統合基盤の整備を早期に進め、2024年度単年で約300億円の価値創出を実現したと公表しています。公的資料によれば、これは単純なITコスト削減ではなく、設備保全の高度化、需給予測精度の向上、顧客向け新サービス創出といった複数の成果が積み重なった結果です。
ForresterやGartnerの分析でも、生成AIやAIエージェントの本格活用企業ほど、ROIを短期的な人件費削減では測らなくなっていると指摘されています。代わりに注目されているのが、従業員体験や将来の柔軟性まで含めた価値評価です。
| ROIの視点 | 評価対象 | 価値の具体例 |
|---|---|---|
| 従来型ROI | コスト削減 | 手作業削減、運用費圧縮 |
| ROE | 従業員体験 | 情報探索時間の短縮、創造業務への集中 |
| ROF | 将来競争力 | 新AI技術への迅速対応、市場投入の前倒し |
例えば、データサイロが解消された企業では、AIエージェントが部門横断で同一のマスターデータと意味定義を参照できるため、新たな業務自動化やサービス企画を数週間単位で立ち上げられるようになっています。Gartnerによれば、このアジリティの差が中長期的な企業価値に大きな開きを生むとされています。
結果として、統合データ基盤への投資は、コスト削減を超えて売上拡大、意思決定の質向上、人材の生産性向上を同時に実現するレバーとなっています。2026年におけるROIの本質は、削った金額ではなく、データがつながったことで新たに生まれた価値の総量にあると言えるでしょう。
参考文献
- Qiita:2026年の10のデータマネジメント・トレンド(予測)
- Forrester:Predictions 2026: The Race To Trust And Value
- KDDI Business:「2025年の崖」とは 経済産業省のDXレポートをもとに解説
- デジタル庁:地方公共団体の基幹業務システムの統一・標準化
- IT Leaders:関西電力、DXとデータ活用で300億円の価値創出
- Gartner:Gartner Top 10 Strategic Technology Trends for 2026