生成AIの活用が当たり前になった今、多くの企業で「データはあるのに使えない」という違和感が強まっています。部門ごとに分断されたデータ、用途別に乱立するAI、そして連携できない基幹システム。これらは単なるITの課題ではなく、企業競争力そのものを左右する経営課題へと変化しています。
2026年現在、AIはチャットボットから自律的に業務を遂行するAIエージェントへと進化しました。その結果、データ統合に求められる水準も、人間が理解できるレベルから、AIが誤解なく行動できるレベルへと一段引き上げられています。曖昧な定義や不完全な連携は、即座に誤判断や業務停止につながるリスクとなります。
本記事では、データサイロがなぜ今これほど深刻な問題となっているのかを起点に、AIサイロという新たな脅威、MDMやセマンティックレイヤーの再評価、Data MeshとData Fabricの融合、さらには日本企業が直面する「2025年の崖」以降の現実までを整理します。AIエージェント時代において、どのような統合データ基盤を選択すべきなのか。その全体像と意思決定のヒントを得られる内容です。
2026年にデータサイロが経営課題へと変わった理由
2026年にデータサイロが経営課題へと格上げされた最大の理由は、生成AI、とりわけ自律型AIエージェントが企業活動の中枢に入り込んだからです。かつてデータサイロは、IT部門や情報システム部門が抱える技術的な非効率として認識されていました。しかし現在では、**サイロ化したデータそのものが、企業の意思決定速度と正確性を直接的に劣化させる要因**になっています。
Forresterが2026年の予測で指摘している通り、企業におけるAI活用は「試験導入の段階」を終え、明確な事業価値を求められるフェーズに入りました。この変化の中で、AIは人間を補助するチャットボットから、複数システムを横断して業務を遂行するAIエージェントへと進化しています。ERP、CRM、SCMなどにまたがる処理をAIが自律的に実行する時代において、データが分断されている状態は、単なる不便さでは済まされません。
人間であれば、部門ごとに異なる数値定義や表記揺れがあっても、会話や経験則で補正できます。しかしAIエージェントは、定義されたデータを前提に確率計算と論理処理を行います。そのため、**部門ごとに意味が異なるデータが存在すると、誤った自動判断が高速かつ大量に連鎖するリスク**が顕在化します。Gartnerも、生成AIのハルシネーション対策において「データ定義の統一」が最優先事項であると強調しています。
| 観点 | 2020年代前半 | 2026年現在 |
|---|---|---|
| データサイロの位置付け | IT効率の問題 | 経営リスク |
| 主な影響範囲 | 分析・レポート | 意思決定・自動実行 |
| 問題発覚の速度 | 遅い(人が気づく) | 速い(AIが即時処理) |
さらに2026年特有の要因として、「AIサイロ」の出現があります。汎用LLMの限界が明確になり、製造、財務、マーケティングなど業務特化型のAIが乱立する中で、それぞれが独自のデータと定義を前提に動き始めています。IDCの予測では、AIエージェントの利用増加により、APIコール量は数年で桁違いに増大するとされていますが、**共通のデータ基盤を欠いたままでは、組織全体の最適化は不可能**です。
日本企業にとっては、「2025年の崖」を越えた後の現実もこの問題を深刻化させています。経済産業省が警告した通り、老朽化した基幹システムが部門ごとに残存し、データが囲い込まれた結果、AIに必要なデータを即座に提供できない企業が増えました。これはコスト増ではなく、**AI前提の市場競争から排除されるという経営上の機会損失**を意味します。
このように2026年のデータサイロ問題は、技術、組織、競争環境の変化が同時に重なった結果として顕在化しています。データがつながらないことは、AIが正しく判断できないことを意味し、その責任は最終的に経営に帰結します。だからこそ今、データサイロは現場レベルの改善課題ではなく、経営が直接向き合うべき中核テーマとして認識されているのです。
チャットボットからAIエージェントへ進化する企業システム
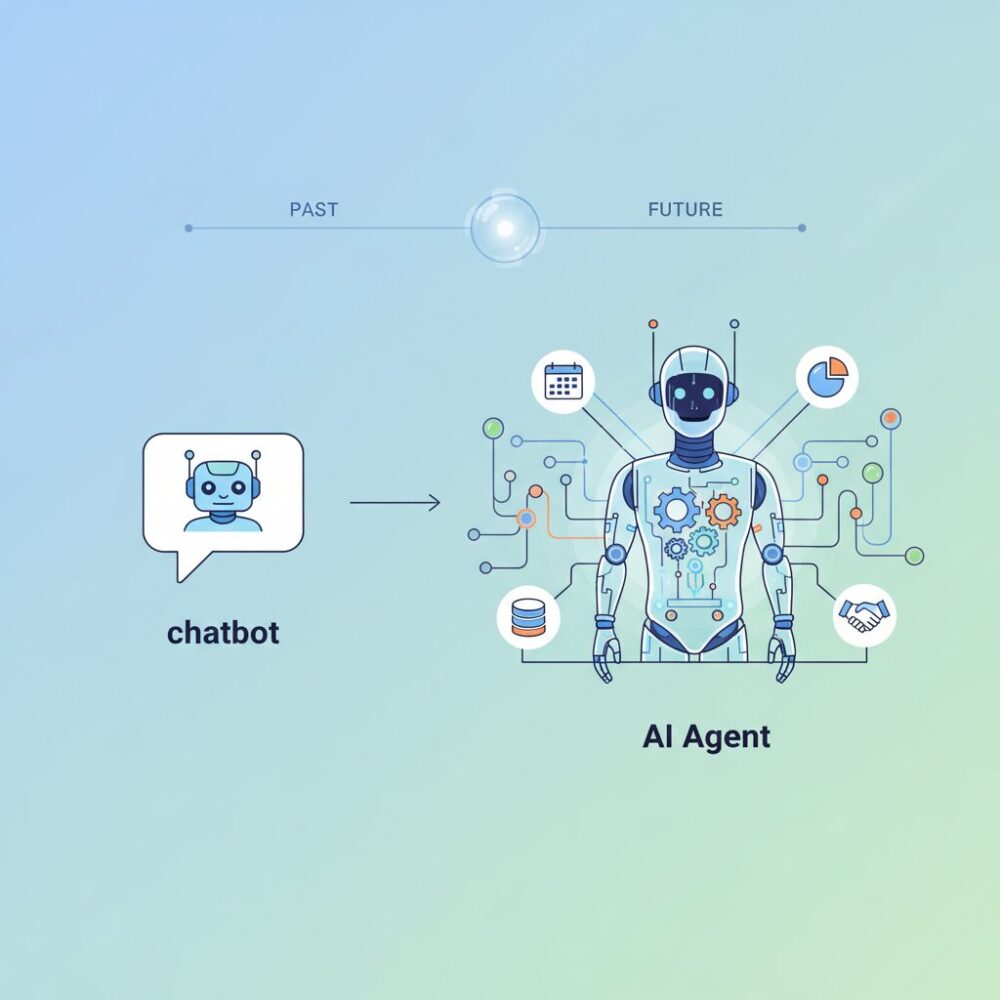
企業システムにおけるAI活用は、2026年を境に明確な転換点を迎えています。これまで主流だったチャットボット型AIは、人間の質問に対して情報を返す受動的な存在でしたが、現在は業務プロセスそのものを実行するAIエージェントへと進化しています。この変化はUIの高度化ではなく、企業システムの設計思想そのものを変えるインパクトを持っています。
Forresterの2026年予測によれば、生成AIの「実験フェーズ」は終わり、企業は明確な価値創出を求める段階に入っています。その中核に位置付けられているのが、自律的に判断し、複数システムを横断してタスクを遂行するAIエージェントです。ERPで在庫を確認し、CRMで顧客履歴を参照し、購買や物流まで自動実行するような動きは、すでに一部の先進企業では現実のものとなっています。
IDCは、主要企業におけるAIエージェントの利用が2027年までに10倍に拡大し、APIコールやトークン消費量は1,000倍規模に達すると予測しています。これは、AIが単なる問い合わせ窓口ではなく、企業システムの新たな利用者=デジタル労働者として位置付けられ始めていることを意味します。
| 観点 | 従来のチャットボット | AIエージェント |
|---|---|---|
| 役割 | 質問応答・補助 | 業務の自律実行 |
| データ利用 | 人間向け表示中心 | 機械可読・高精度前提 |
| 影響範囲 | 個別業務 | 全社横断プロセス |
この進化が企業にもたらす最大の変化は、データ統合の要件です。人間が利用する前提であれば、多少の表記揺れや定義の違いは経験則で補完できました。しかしAIエージェントは論理と確率で動作するため、曖昧なデータ定義は誤判断や誤った自動処理に直結します。生成AIにおけるハルシネーションの多くは、モデル性能ではなく入力データの品質に起因すると指摘されています。
Forresterが述べるように、エンタープライズソフトウェアはユーザー中心設計から、労働者およびプロセス中心設計へ移行しています。ここで言う労働者には、人間だけでなくAIエージェントが含まれます。つまり、企業システムは「人が使いやすい画面」よりも、AIが安全かつ一貫した判断を下せる構造を優先して設計される段階に入ったのです。
この視点に立つと、チャットボットの延長線上でAIを捉える発想は限界を迎えています。AIエージェントは、もはや付加機能ではなく、業務そのものを担う存在です。そのため企業システムは、AIが正しく理解し、行動できることを前提としたデータ品質、定義、連携の再設計を迫られています。チャットボットからAIエージェントへの進化は、企業システムが人間中心から人間とAIの協働基盤へ変わることを意味しています。
部門分断を超えた新リスク「AIサイロ」の正体
従来、企業におけるサイロ問題は部門やシステムの分断として語られてきました。しかし2026年現在、それを上回る深刻さで浮上しているのが、部門分断を横断して発生する新リスク、いわゆるAIサイロです。これは単なるデータの孤立ではなく、組織内に存在する複数のAI同士が意味的に連携できない状態を指します。
背景には、汎用LLMから領域特化型言語モデルへの急速なシフトがあります。製造、財務、マーケティング、法務など、それぞれの業務に最適化されたAIは高い精度を発揮する一方、学習データや前提となる定義が異なるため、同じ言葉でも解釈が一致しません。**この意味の不整合こそがAIサイロの本質です。**
例えば「売上」という指標一つでも、マーケティングAIは受注ベース、財務AIは請求や入金ベースで理解するケースがあります。人間同士であれば会議や資料で調整できますが、自律的に高速処理を行うAIエージェント間では、そのズレが自動処理の誤作動として顕在化します。Forresterが指摘するように、AIエージェント時代では小さな定義差が大きな経営リスクに直結します。
| 観点 | 従来のデータサイロ | AIサイロ |
|---|---|---|
| 主な原因 | 部門・システム分断 | AIごとの意味定義・学習差 |
| 問題の表出 | 分析遅延・二重管理 | 誤判断・誤自動化の連鎖 |
| 影響範囲 | 特定部門 | 全社・経営判断 |
AIサイロが厄介なのは、表面上は業務が回っているように見える点です。各部門のAIはそれぞれ成果を出しているため、問題が顕在化した時には既に意思決定や取引処理が実行された後、というケースも少なくありません。Gartnerが警告するように、生成AIのTCOにはハルシネーション対策や再学習コストが含まれ、AIサイロはそのコストを指数関数的に押し上げます。
さらに、日本企業特有の事情として、部門最適の文化と長年の業務慣行がAIサイロを助長しています。各部門が自律的にAIを導入しやすくなった一方で、全社共通の意味定義やルール作りが後回しにされがちです。**結果として、AIは増えたが組織知は統合されていないという逆説的な状況が生まれています。**
重要なのは、AIサイロが技術の失敗ではなく、設計思想とガバナンスの欠如から生じている点です。IDCが予測するように、今後AIエージェントの利用は爆発的に増加します。その前提として、AI同士が参照する言葉や指標、IDが一致していなければ、企業は自律化の恩恵ではなく混乱を享受することになります。
AIサイロは見えにくく、気づいた時には手遅れになりやすい新しい経営リスクです。だからこそ、データ量やモデル性能よりも先に、意味と前提を揃える視点が2026年のデータ戦略において決定的に重要になっています。
共通言語として再評価されるMDMとセマンティックレイヤー

AIエージェントが業務の主体となり始めた2026年において、MDMとセマンティックレイヤーは「古くて新しい基盤」として再評価されています。**両者の本質的な役割は、組織とAIに共通言語を与えること**にあります。特に特化型AIが乱立する現在、データそのものよりも「意味の揃い方」が競争力を左右する段階に入っています。
MDMは、顧客・商品・取引先といった企業活動の中核となるエンティティに、一貫した識別子と正規データを与える仕組みです。ForresterやGartnerの分析によれば、AIエージェント活用が進んだ企業ほど、MDMを単なる名寄せ基盤ではなく、AIの判断根拠となる信頼の源泉として位置付けています。AIが自律的にERPやCRMを横断する以上、参照する顧客や製品の定義が揺らげば、誤った自動処理が連鎖的に発生します。
一方、セマンティックレイヤーは、KPIや業務指標の計算ロジック、ビジネス用語の意味を機械可読な形で統一する層です。**MDMが「名詞」を揃える仕組みだとすれば、セマンティックレイヤーは「動詞と文法」を揃える存在**だと捉えると理解しやすいでしょう。IDCやGartnerは、マルチエージェント環境ではセマンティック定義の不一致が最大のボトルネックになると指摘しています。
| 観点 | MDM | セマンティックレイヤー |
|---|---|---|
| 主な対象 | 顧客・商品・組織などのマスター | KPI・指標・業務用語 |
| AIへの価値 | 参照すべき正のデータを保証 | 計算・解釈の一貫性を保証 |
| 欠如した場合のリスク | AIサイロによるID不整合 | 指標解釈のズレによる誤判断 |
実務では、両者を分断して考えること自体がリスクになります。例えば「売上」という指標をAIが扱う場合、MDMで顧客IDや商品IDが統一されていても、セマンティックレイヤーで計算定義が共有されていなければ、部門別AIが異なる数値を前提に行動してしまいます。**MDMとセマンティックレイヤーはセットで初めて、AIエージェントにとっての共通認識基盤として機能します。**
2026年時点の先進企業では、これらを人間向けBIの裏方ではなく、API経由でAIに直接提供する設計が主流です。Gartnerが示すように、AIネイティブなデータ基盤では「人が読む定義書」ではなく「AIが参照する意味モデル」が価値を持ちます。MDMとセマンティックレイヤーの再評価は、AI時代におけるデータガバナンスの実践的な回答と言えるでしょう。
Data MeshとData Fabricが融合する最新アーキテクチャ
2026年現在、Data MeshとData Fabricは対立概念ではなく、実運用に耐える形で融合したアーキテクチャとして再定義されています。GartnerやForresterの最新分析によれば、AIエージェントが部門横断で自律的に動作する環境では、中央集権か分散かという二元論自体がもはや現実的ではないとされています。求められているのは、組織構造と技術基盤を分離して設計する発想です。
具体的には、データの意味や品質責任は各ドメインが担い、データをプロダクトとして提供するというData Meshの思想を採用しつつ、データ探索、接続、セキュリティ適用、メタデータ管理といった共通機能はData Fabricとして中央で提供します。**ガバナンスと自律性を同時に成立させる設計**が、この融合モデルの本質です。
| 観点 | Data Meshの役割 | Data Fabricの役割 |
|---|---|---|
| 責任主体 | 各事業ドメイン | IT部門・CoE |
| 主な関心 | 意味定義・品質・価値 | 接続性・自動化・統制 |
| AIとの関係 | 業務文脈の反映 | 横断利用と安全性 |
この構成が注目される最大の理由は、AIエージェント時代のデータ消費構造にあります。IDCは、AIエージェントによるAPIアクセスが指数関数的に増加し、人手による調整が介在しないデータ連携が主流になると予測しています。その際、中央ITがすべてのデータ定義を握るモデルではスケールせず、逆に完全分散では意味の不整合が暴走を招きます。
融合アーキテクチャでは、セマンティックレイヤーとMDMをData Fabric側に組み込み、全ドメイン共通の機械可読な定義を提供します。一方で、その定義をどう使い、どのKPIを重視するかは各ドメインが決めます。**意味の共通化と意思決定の分散を切り分けること**で、AI同士が誤解なく連携できる環境が整います。
日本企業においても、この融合モデルは現実解として受け入れられ始めています。特にレガシーシステムを抱える企業では、既存資産を活かしながら段階的にData Fabricを敷設し、その上でドメイン単位のデータプロダクト化を進めるケースが増えています。Forresterが指摘するように、成功の鍵は技術選定ではなく、責任分界点を明確にしたアーキテクチャ設計にあります。
Data MeshとData Fabricの融合は、データサイロ解消のゴールではありません。**AIエージェントが安全かつ高速に価値を生み続けるための、持続可能な前提条件**として、2026年の標準アーキテクチャになりつつあります。
RAG本番運用で顕在化するベクトルデータのサイロ問題
RAGを本番運用に移行した企業で、2026年に顕在化しているのがベクトルデータのサイロ問題です。PoC段階では有効だった小規模なベクトルデータベースが、部門別・用途別に乱立し、結果として生成AIの品質と信頼性を大きく損なっています。
背景には、2024〜2025年にかけて各部署が独自にRAGを試行した経緯があります。FAQ用、法務文書検索用、営業支援用といった具合に、目的ごとにドキュメントをベクトル化し、更新や廃棄のルールを定めないまま本番利用が続けられました。その結果、同じ社内規程について複数の埋め込み表現が存在し、AIの回答が利用するベクトルによって微妙に食い違う事態が頻発しています。
ForresterやGartnerの分析でも、RAGの失敗要因として「ベクトルデータのライフサイクル管理不在」が繰り返し指摘されています。特に深刻なのがデータの陳腐化です。元文書が改訂されても再インデックスが行われず、AIが旧ルールや過去の数値を前提に回答してしまうケースが、金融・製薬・公共分野で実害として報告されています。
| 問題領域 | 本番環境での影響 | 経営・業務リスク |
|---|---|---|
| 更新管理 | 古いベクトルが残存 | 誤判断・コンプライアンス違反 |
| 権限制御 | ACLが継承されない | 情報漏えい・内部不正 |
| 重複生成 | 意味的に近い埋め込みが乱立 | 回答品質のばらつき |
もう一つの重大な論点が権限管理の断絶です。元ドキュメントでは厳密なアクセス制御が施されていても、ベクトル化の過程でメタデータが失われると、AI経由で本来閲覧できない情報に到達してしまいます。これは従来のDWHや検索基盤にはなかった、RAG特有のガバナンス課題です。
先進企業ではこの問題に対し、VectorOpsやLLMOpsの考え方を導入しています。具体的には、ベクトル生成をアドホックな処理から切り離し、データリネージ、更新検知、アクセス権メタデータを含む自動パイプラインとして管理します。どの文書から、いつ生成され、どのAIが参照可能かを可視化することで、RAGを単なる検索補助ではなく、信頼できる業務基盤へと昇華させています。
RAGの本質的な価値は、生成AIに社内知を安全かつ最新の形で供給する点にあります。ベクトルデータがサイロ化したままでは、AIエージェントが高速に誤りを拡散するだけです。ベクトルもまた第一級の業務データであるという認識への転換が、2026年のRAG本番運用における分水嶺になっています。
2025年の崖を越えた日本企業が直面する現実
2025年の崖を越えた日本企業の多くは、劇的な崩壊ではなく、より静かで深刻な現実に直面しています。経済産業省のDXレポートが示した年間最大12兆円の経済損失は、2026年時点で一気に顕在化したわけではありませんが、**競争力の差として確実に企業間に刻み込まれ始めています**。
最大の変化は、ITがもはや業務効率化の手段ではなく、事業継続そのものを左右する基盤になった点です。レガシーシステムを抱え続けた企業では、IT予算の約8割が保守運用に固定化され、新規事業やAI活用への投資余力が著しく制限されています。これはKDDI Businessなどの分析でも繰り返し指摘されており、**攻めのDXが構造的に不可能な状態**に陥っています。
さらに深刻なのが人材面です。COBOLなど旧来技術に依存したシステムは、属人化とブラックボックス化が進み、ベテラン退職と若手不在という二重苦を生んでいます。軽微な改修に数カ月を要するケースも珍しくなく、AIエージェントを前提としたスピード経営から完全に取り残されています。
| 項目 | 刷新が進んだ企業 | 先送りした企業 |
|---|---|---|
| IT予算配分 | 成長投資比率が高い | 保守運用が大半 |
| AI活用 | 業務プロセスに組み込み済み | PoC止まり |
| データ連携 | 全社横断で可能 | 部門ごとに分断 |
特に見過ごせないのがデータサイロの固定化です。生成AIやAIエージェントが標準インフラとなった2026年において、APIを持たない、構造が不明瞭なデータは事実上「使えない資産」です。Forresterの分析によれば、AI導入の成否はアルゴリズムではなく、**データに即時アクセスできるかどうか**で決まるとされています。
結果として、2025年の崖を越えられなかった企業は、市場から徐々に存在感を失う「緩やかな退場」に直面しています。これはコストの問題ではなく、競争の土俵に立てるかどうかの問題です。**崖の本質はITではなく、経営の時間切れ**であったことが、2026年の現実として突きつけられています。
iPaaSとデータ連携ツールの進化がもたらす変化
2026年において、iPaaSとデータ連携ツールは単なるシステム接続の手段ではなく、企業の競争力を左右する中核的な基盤へと進化しています。背景にあるのは、AIエージェントの実運用フェーズへの移行と、データサイロが経営リスクとして顕在化した現実です。Forresterの予測が示す通り、企業はもはや「つながるかどうか」ではなく、**「どう賢く、どう安全につなぐか」**を問われています。
特に大きな変化は、iPaaSがインテグレーションの自動化だけでなく、可観測性やガバナンスを内包し始めた点です。従来はデータ連携後の障害検知や影響分析は別ツールに委ねられていましたが、2026年のiPaaSはデータフロー全体をリアルタイムで把握し、異常を即座に検知・通知する設計が主流になりつつあります。これはSREの考え方がデータ連携領域に持ち込まれた結果だといえます。
iPaaSは「土管」から「神経系」へと役割を変え、データと業務の状態を常時可視化する存在になっています。
もう一つの進化が、ノーコード・ローコード化による利用者層の拡大です。日本市場ではBizteX ConnectやYoomのように、現場部門が自らSaaS同士を連携させるユースケースが急増しています。IT部門を介さずとも業務改善が進む一方で、連携が無秩序に増えるリスクもあります。そのため2026年のツールは、権限管理や変更履歴、承認フローを標準機能として備え、現場主導と統制の両立を図っています。
| 進化の軸 | 2026年の特徴 | ビジネスへの影響 |
|---|---|---|
| 可観測性 | データ遅延・欠損をリアルタイム検知 | 障害対応の迅速化と信頼性向上 |
| 民主化 | 非エンジニアによる連携設計 | 現場DXの加速と改善サイクル短縮 |
| AI連携 | 生成AIアダプターの標準搭載 | データ整形・判断の自動化 |
さらに注目すべきは、生成AIとの融合です。ASTERIA Warpなどが提供するAIアダプターにより、曖昧な表記や非構造データをAIが解釈し、正規化した上で次のシステムへ渡す設計が一般化しています。これにより、従来は人手に頼っていたデータクレンジング工程が大幅に短縮されました。Gartnerが指摘するように、AI活用のROIは前処理の質に大きく左右されるため、この進化は実務上の価値が極めて高いといえます。
結果として、iPaaSは企業のデータ戦略における「接着剤」ではなく、「判断を伴うハブ」へと位置づけが変わりました。データをただ流すのではなく、意味を補い、品質を高め、次のAIや業務プロセスにつなげる。その役割を担うiPaaSの進化こそが、2026年のデータ連携の質的転換を象徴しています。
セキュリティとガバナンスを両立する分散データ管理
分散データ管理が常態化した2026年において、最大の経営課題の一つが、セキュリティとガバナンスをいかに両立させるかです。クラウドやデータメッシュの普及により、データは物理的に各所へ分散しましたが、統制まで分散させてしまうと、AIエージェント時代では致命的なリスクとなります。
特に注目されているのが、Apache IcebergやDelta Lakeに代表されるオープンテーブルフォーマットの広がりです。これによりベンダーロックインは回避しやすくなりましたが、SnowflakeやDatabricksなど複数基盤を横断した際、アクセス制御やマスキングルールが一貫しない「セキュリティサイロ」が新たに生まれました。ガートナーの分析でも、データ侵害事故の多くがこの設定不整合に起因すると指摘されています。
この課題に対し、2026年時点で主流となりつつあるのがポリシー・メタデータ駆動型のガバナンスです。データの所在に依存せず、誰が・どの文脈で・どのAIエージェントとしてアクセスするかを判断する中央のポリシーエンジンを介在させます。実体は分散、統制は集中という設計思想が、セキュリティと俊敏性の両立を可能にしています。
| 観点 | 従来型 | 2026年型分散ガバナンス |
|---|---|---|
| アクセス制御 | 基盤ごとに個別設定 | 中央ポリシーで動的制御 |
| AI利用 | 人ユーザー前提 | AIエージェント前提 |
| リスク | 設定漏れ・属人化 | メタデータで可視化 |
さらに重要なのが、RAGやVectorDBを含むAI実装領域です。ベクトル化されたデータは元データの権限を引き継がないケースが多く、AI経由での機密情報漏洩が現実の問題として顕在化しました。これを防ぐため、データリネージと可観測性を組み込んだVectorOpsやLLMOpsが整備され、ガバナンスの適用範囲はAIの内部処理まで拡張されています。
また、日本ではデジタル庁やDSAが推進するエリアデータ連携基盤の文脈で、データ主権の考え方が企業にも波及しています。データは共有するが、コントロール権は手放さないという設計は、企業間連携や業界横断AIにおいても重要です。ガバナンスは制約ではなく、信頼を担保する競争力の源泉であるという認識が、分散データ管理の成否を分ける段階に入っています。
ROIはどう変わるのか――AI時代の新しい価値指標
AIエージェントが業務の中核を担い始めた2026年、ROIの考え方は大きく変化しています。従来のROIは「投資額に対してどれだけコストを削減できたか」「人件費を何%圧縮できたか」といった短期的・定量的な指標が中心でした。しかし、AI時代においては、これだけでは投資価値を正しく測れなくなっています。
Gartnerの分析によれば、生成AI関連投資の総所有コストは、モデル運用、再学習、ガバナンス対応、ハルシネーション監視などの継続コストによって、初期試算を大幅に上回るケースが珍しくありません。つまり、単年度のコスト削減額だけを分子に置くROIでは、AIやデータ基盤投資は「割に合わない」と誤って判断されがちなのです。
この反省から注目されているのが、ROIを拡張した価値指標です。特に議論が進んでいるのが、従業員と将来価値に焦点を当てた指標であり、ROIを補完する役割を果たします。
| 指標 | 評価対象 | AI・データ統合との関係 |
|---|---|---|
| ROI | 短期的な費用対効果 | 自動化や効率化の成果を測定 |
| ROE | 従業員体験・生産性 | データ探索時間削減、意思決定速度向上 |
| ROF | 将来の競争優位性 | 新AI技術への即応力、事業転換の柔軟性 |
ROEはReturn on Employeeの略で、AIや統合データ基盤によって従業員がどれだけ付加価値の高い仕事に集中できるようになったかを測ります。データサイロが解消され、必要な情報を探す時間が減るだけでも、意思決定の質とスピードは大きく向上します。Forresterが指摘するように、AIエージェントと連携する業務環境では、従業員満足度と生産性が連動して高まる傾向が確認されています。
一方のROFはReturn on Future、すなわち将来への投資対効果です。これは「今の投資が、将来どれだけ早く・安全に新しい価値を生み出せるか」を評価します。例えば、データ統合とセマンティック定義が整備されていれば、新しいAIモデルや規制対応が登場した際にも、競合より数カ月早く実装できる可能性があります。この時間差こそが、AI時代の競争力の源泉です。
重要なのは、ROIが不要になったわけではなく、ROIだけでは不十分になったという点です。コスト削減という守りの成果に加え、人と組織の進化、そして将来の選択肢をどれだけ増やせたかを可視化することが、AI時代の経営判断には欠かせません。ROIは単なる数字から、企業の持続的価値を読み解くための多層的な指標へと進化しているのです。
参考文献
- Qiita:2026年の10のデータマネジメント・トレンド(予測)
- Forrester:Predictions 2026: The Race To Trust And Value
- KDDI Business:「2025年の崖」とは 経済産業省のDXレポートに触れながらわかりやすく解説
- デジタル庁:地方公共団体の基幹業務システムの統一・標準化
- IT Leaders:JDMCが「2025年データマネジメント賞」を発表、大賞の関西電力はDX/データ活用で300億円の価値創出
- Gartner:Gartner Top 10 Strategic Technology Trends for 2026