
生成AIの活用やDXの加速が進む中で、「社内にデータは大量にあるのに、使いこなせていない」と感じている方は少なくありません。実際、多くの企業ではデータの所在や意味が分からず、分析やAI活用の初期段階で立ち止まってしまうケースが増えています。
こうした課題の中心にあるのが、データを“探せない・信頼できない・説明できない”という構造的な問題です。2026年現在、この問題を解決する鍵として注目されているのが、従来の「静的な一覧表」から大きく進化した次世代データカタログです。
本記事では、デ确保立を左右する生成AIとの関係性、市場動向、日本特有の規制や政策、そして先進企業の実践事例までを体系的に整理します。データカタログを単なるITツールではなく、経営と現場をつなぐ戦略基盤として捉え直すことで、これからのデータマネジメントの全体像と実践のヒントが得られるはずです。
2026年に起きたデータカタログのパラダイムシフト
2026年に起きた最大の変化は、データカタログが「探すための道具」から「意思決定とAI活用を支える基盤」へと役割を根本的に変えた点にあります。かつてのデータカタログは、データアナリストやエンジニアがテーブル名やカラム定義を確認するための静的な辞書に近い存在でした。しかし生成AIの実装が一般化した現在、その位置付けは企業全体の競争力を左右するインテリジェンス・インフラへと昇華しています。
背景にあるのは、データ量とデータ種別の爆発的増加です。構造化データだけでなく、テキスト、画像、ログといった非構造化データが日常的に分析対象となり、人手によるメタデータ管理は完全に限界を迎えました。この課題に対し、2026年の先進企業ではAIが自律的にメタデータを生成・更新するアクティブメタデータのアプローチが主流となっています。**メタデータが常に最新で、かつ利用状況や文脈を反映して変化し続ける**ことが、前提条件になりつつあります。
ガートナーやAlationの分析によれば、生成AIの精度と信頼性は、参照するデータの意味情報に大きく依存します。AIがカラム名やテーブル構造の背後にあるビジネス上の意味を理解できなければ、もっともらしい誤回答、いわゆるハルシネーションを避けることはできません。ここでデータカタログは、AIにとってのセマンティックレイヤーとして機能します。
| 観点 | 従来型データカタログ | 2026年型データカタログ |
|---|---|---|
| 役割 | データ探索用の静的辞書 | 意思決定とAI活用の基盤 |
| 更新方法 | 人手による手動更新 | AIによる自動生成・学習 |
| 価値 | 作業効率の向上 | ビジネスリスク低減と価値創出 |
特に重要なのは、AIがカタログの利用者であると同時に構築者になっている点です。主要なデータカタログ製品では、AIエージェントがデータベースをスキャンし、説明文の自動生成や個人情報の検出、利用頻度に基づく信頼度評価までを行います。これにより、長年課題とされてきた「作ったが更新されず陳腐化するカタログ」からの脱却が現実のものとなりました。
さらに、ハイブリッドクラウドやマルチクラウドが前提となった2026年において、データは物理的に分散する一方です。データファブリックやデータメッシュといった分散型アーキテクチャの下では、データを一箇所に集約するのではなく、論理的につなぐ役割が求められます。**この接着剤として機能するのが、進化したデータカタログ**です。
従来の門番型ガバナンスでは、スピードと柔軟性が犠牲になっていました。2026年型のカタログは、アクセス権やポリシーを自動で適用するガードレール型ガバナンスを実現し、安全性を保ちながらデータ活用を促進します。IDC Japanも、国内企業におけるデータ関連投資が減速局面でも成長を維持している要因として、この構造的変化を挙げています。
このように2026年のデータカタログは、単なるITツールではありません。企業のデータがどこから来て、どのように使われ、どの意思決定に影響しているのかという文脈を一元的に提供する存在です。**データを資産として機能させるための前提条件そのものが、データカタログに集約された**と言えるでしょう。
生成AI活用を左右するデータカタログの役割
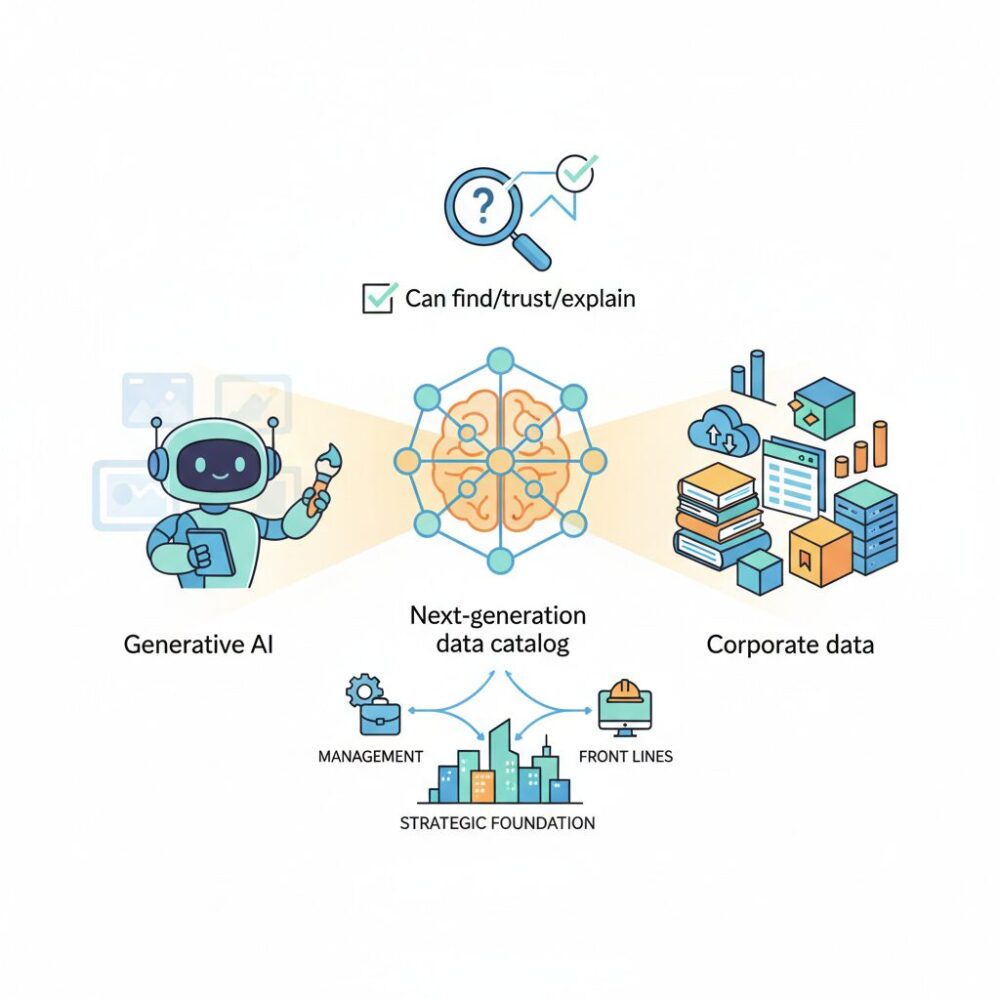
生成AI活用の成否を分ける最大の要因は、モデルの性能そのものではなく、参照されるデータの信頼性と意味づけにあります。**データカタログは、生成AIにとっての事実上の「思考の土台」として機能します**。2026年現在、多くの企業がLLMを業務に組み込む中で、ハルシネーション対策として最も重視しているのが、この土台の整備です。
スタンフォード大学のHuman-Centered AI研究でも指摘されている通り、生成AIの誤回答の多くは推論ロジックではなく、入力データの曖昧さや文脈欠如に起因します。データカタログは、データの定義、利用条件、鮮度、責任者といったメタデータを一元管理し、AIが参照すべき「正解の範囲」を明示します。
| 観点 | カタログ未整備 | カタログ整備済み |
|---|---|---|
| データ定義 | 部門ごとに解釈が異なる | 統一されたビジネス定義 |
| AI回答精度 | もっともらしい誤答が発生 | 根拠付きで説明可能 |
| ガバナンス | 責任所在が不明瞭 | オーナーと利用条件が明確 |
特に重要なのが、データカタログが生成AIのセマンティックレイヤーとして機能する点です。物理的なカラム名やファイル名を、人間とAIの双方が理解できるビジネス概念へ翻訳することで、AIは質問の意図を正確に解釈できます。例えば「今期の国内売上は?」という問いに対し、どの期間・通貨・税区分のデータを参照すべきかを判断できるのは、カタログに定義された意味情報があるからです。
さらに2026年の先進事例では、AIがカタログを読むだけでなく、更新する側にも回っています。主要ベンダーの調査によれば、AIによる自動説明文生成やPII検出により、メタデータ整備工数は従来比で50〜70%削減されています。これにより、カタログが陳腐化するリスクが大幅に低下しました。
生成AI活用を本格化させたい企業にとって、データカタログは後付けの管理ツールではありません。**AIの判断根拠を支え、説明責任と信頼性を担保する中核インフラ**として位置づけることが、2026年時点での実務的な共通認識になりつつあります。
データファブリック時代におけるガバナンスの要
データファブリック時代において、ガバナンスは「制約」ではなく「信頼を前提にした加速装置」として再定義されています。クラウド、オンプレミス、SaaSにまたがりデータが分散する環境では、すべてを中央集権的に管理する従来型ガバナンスは現実的ではありません。そこで中核となるのが、データカタログを軸にした分散型ガバナンスです。誰が、どのデータを、どの条件で使えるのかを事前に明示し、迷わず安全に活用できる状態を作ることが最大の目的です。
この考え方は、データファブリックの基本思想である「物理的に集めず、論理的に統合する」アーキテクチャと強く結びついています。各ドメインが自律的にデータを管理しながらも、ガバナンスのルールそのものはカタログ上で統一されます。AlationやCollibraなどの先進的ツールでは、アクティブメタデータを通じて、アクセス権限や機密区分がデータ基盤側に自動反映される仕組みが一般化しています。これにより、人手による申請や確認を待たずに、ポリシーが即時に執行されます。
| 観点 | 従来型ガバナンス | データファブリック型ガバナンス |
|---|---|---|
| 管理主体 | 中央IT部門 | 各ドメイン+共通ルール |
| 運用方法 | 手動・承認フロー中心 | ポリシー自動適用 |
| データ活用速度 | 遅い | 速い |
特に重要なのが、生成AI時代との接点です。スタンフォード大学や大手調査機関の指摘によれば、AI活用における最大のリスクはモデルそのものではなく、参照データの不透明さにあります。データカタログがガバナンスのコントロールプレーンとして機能することで、AIは「信頼できるデータのみ」を参照することが可能になります。どのデータが公式で、どれが参考値なのかをAI自身が判断できる状態が、ハルシネーション抑止の現実解とされています。
日本においても、この流れは制度面から後押しされています。デジタル庁が推進する包括的データ戦略やGIFの標準化は、企業内ガバナンス設計にも直接影響を与えています。データ定義や来歴をカタログで明示できる企業ほど、将来の外部連携や規制対応コストを抑えられることが、先進事例から明らかになっています。データファブリック時代のガバナンスとは、分散を前提にしながら、信頼だけは一元化する仕組みであり、その要としてデータカタログが不可欠な存在になっているのです。
急成長するデータカタログ市場と世界的トレンド

2026年に向けてデータカタログ市場は世界的に急成長を続けており、企業のIT投資の中でも戦略性の高い分野として位置づけられています。複数の市場調査によれば、グローバル市場は2025年時点で約12.7億ドル規模とされ、2030年代前半にかけて年平均成長率20%前後という高水準で拡大する見通しです。これは単なるツール需要ではなく、**AI活用とガバナンスを同時に成立させる基盤投資**として認識が変化していることを意味します。
この成長を牽引する最大の要因は、生成AIの業務実装が一気に進んだことです。Mordor IntelligenceやFortune Business Insightsなどの分析によれば、LLMの精度や説明責任を担保するために、AIが参照するデータの意味や来歴を管理できる仕組みが不可欠となり、データカタログがその中核を担っています。**AIの信頼性確保という経営課題が、市場拡大を直接押し上げている**点は2026年の大きな特徴です。
| 地域 | 市場動向の特徴 | 主な成長ドライバー |
|---|---|---|
| 北米 | 成熟市場だが成長継続 | 生成AIと厳格な規制対応 |
| 欧州 | 安定的な拡大 | GDPRを中心とした法規制 |
| アジア太平洋 | 最も高い成長率 | DX投資とクラウド移行 |
また、世界的なデータ規制の強化も市場成長を後押ししています。GDPRやCCPAに加え、日本の改正個人情報保護法など、各国で説明責任と追跡可能性が求められる中、どのデータがどこで使われているかを即座に把握できる仕組みは必須となりました。Alationの業界レポートでも、**コンプライアンス対応を目的とした導入が全体の4割近くを占める**と指摘されています。
さらに注目すべきは、新興国を含むアジア太平洋地域での伸びです。クラウドネイティブ基盤の普及と同時にデータ活用を始める企業が多く、最初からカタログを前提とした設計が採用されています。これは欧米の「後追い整備」とは異なるトレンドであり、**データカタログが最初から経営インフラとして組み込まれる世界標準**が形成されつつあることを示しています。
日本市場に見るデータカタログ投資の特徴と背景
日本市場におけるデータカタログ投資の最大の特徴は、「攻めのデータ活用」と「守りのガバナンス」を同時に満たすインフラ投資として位置づけられている点にあります。グローバルでは分析効率やAI活用が主目的となるケースが多い一方、日本では法規制対応、レガシー刷新、人材不足といった構造課題への現実的な解として投資判断が行われています。
IDC Japanの分析によれば、2026年の国内IT市場は全体としては成長が鈍化する見通しであるにもかかわらず、データ関連ソフトウェアへの支出はプラス成長を維持するとされています。その背景にあるのが、いわゆる「2025年の壁」以降に本格化した基幹システム刷新です。長年ブラックボックス化してきた業務データを可視化しなければ、クラウド移行やAI導入が前に進まないという認識が、経営層レベルで共有されるようになりました。
この文脈において、データカタログは単なる利便性向上ツールではなく、刷新プロジェクトに伴うリスク低減装置として評価されています。どのデータがどの業務・帳票・レポートに影響するのかを事前に把握できることは、移行失敗による業務停止リスクを避けたい日本企業にとって極めて重要です。実際、国内SIerやコンサルティングファームの間では「大規模更改案件ではカタログ整備が前提条件になる」との見方が一般化しています。
| 投資背景 | 日本市場での特徴 | 意思決定の視点 |
|---|---|---|
| 基幹システム刷新 | データの所在・意味の可視化が最優先 | 移行リスクと障害回避 |
| AI・分析活用 | 全社展開よりも段階的導入 | 再現性と説明責任 |
| 規制・監査対応 | メタデータと文書管理の重視 | 当局・監査への即応性 |
また、日本特有の投資動機として無視できないのが深刻なIT・データ人材不足です。IMARC Groupが示すように、市場規模自体は堅調に拡大しているものの、その多くは「人を増やす代わりに、メタデータ管理を自動化する」ための投資です。AIによる説明文生成や自動タグ付け機能が評価されるのも、属人化した知識を組織に残したいという切実なニーズがあるからです。
さらに、日本市場では政府主導のデータ戦略が民間投資を後押ししています。デジタル庁が推進するベース・レジストリや政府相互運用性フレームワークにより、データ定義やモデルの標準化が進み、企業側も自社カタログをそれに準拠させる動きが広がっています。これは将来の官民データ連携や外部API接続を見据えた、中長期視点の先行投資といえます。
総じて日本におけるデータカタログ投資は、短期的なROIだけでなく、「止めない」「説明できる」「引き継げる」データ基盤を作るための経営判断として行われています。この堅実かつ現実志向の姿勢こそが、日本市場における投資行動の最大の特徴です。
主要データカタログ製品とベンダーの競争構造
2026年のデータカタログ市場では、単なる機能比較ではなく、どのレイヤーで価値を提供するかという競争軸が明確になっています。競争構造は大きく三層に分かれ、それぞれが異なる顧客課題と導入文脈を押さえることで棲み分けが進んでいます。
| セグメント | 代表的ベンダー | 競争優位の源泉 |
|---|---|---|
| グローバル・エンタープライズ型 | Alation、Collibra | 高度なガバナンス、Active Metadata、大規模展開実績 |
| 国内特化・統合型 | Trocco | ETL一体型、日本市場向けUIと支援体制 |
| クラウドネイティブ型 | Google Dataplex、AWS DataZone | クラウド基盤との深い統合とIAM連携 |
AlationやCollibraに代表されるグローバル・エンタープライズ製品は、依然として大企業や規制産業を中心に強い存在感を保っています。特に金融・製薬・通信分野では、**エンドツーエンドのリネージ可視化やポリシー駆動型ガバナンス**が評価され、CDO組織主導の全社導入が進んでいます。Mordor Intelligenceなどの市場分析によれば、これらのベンダーは単価が高い一方で更新率が高く、長期契約モデルによる安定した収益構造を築いています。
一方、日本市場で特徴的なのがTroccoに代表される国内特化・統合型の台頭です。データカタログ単体ではなく、データパイプライン構築からメタデータ管理までを一気通貫で提供する点が評価されています。**エンジニアリソースが限られる中堅〜大手企業にとって、「一つのSaaSで完結する」こと自体が競争優位**となっており、2025年以降のクラウド移行案件で採用が拡大しています。IMARC Groupの日本市場分析でも、導入障壁の低さが成長要因として指摘されています。
クラウドネイティブ型は、Google CloudやAWSを主戦場とする企業にとって事実上の標準になりつつあります。DataplexやDataZoneは、BigQueryやS3、IAMと密接に連動することで、**カタログを意識せずともガバナンスが効く体験**を提供します。IDCの分析によれば、2026年にはこれらがマルチクラウド対応を強化することで、独立系ベンダーの領域に本格的に踏み込み始めています。
重要なのは、2026年時点では「どれが勝者か」ではなく、**自社のアーキテクチャと組織成熟度にどのセグメントが適合するか**が選定基準になっている点です。市場はゼロサムではなく、併用や段階的移行を前提とした競争構造へと進化しており、ベンダー各社もAPI連携や共存戦略を強めています。
政府政策・標準化が企業データ管理に与える影響
政府政策や標準化の動きは、2026年現在、企業のデータ管理の在り方を根本から変えつつあります。特に日本では、デジタル庁が推進する包括的データ戦略が、単なる行政効率化にとどまらず、民間企業のデータマネジメント実務にまで直接的な影響を与えています。もはや政府の指針は「参考情報」ではなく、企業データ基盤設計の前提条件として扱われる段階に入っています。
象徴的なのが、ベース・レジストリの社会実装です。法人番号や住所といった基礎データが国主導で標準化・API提供され始めたことで、企業側は自社データをこれらの公的データと突合・連携させる責任を負うようになりました。デジタル庁の説明によれば、住所ベース・レジストリの統一により、名寄せやデータクレンジングにかかるコストが大幅に削減できるとされています。一方で、自社の顧客データがどのレジストリ項目に対応しているのかを即座に説明できない企業は、連携の恩恵を受けられません。この説明責任を支えるのが、データカタログによるメタデータ管理です。
| 政策・標準 | 企業データ管理への影響 | 求められる対応 |
|---|---|---|
| ベース・レジストリ | 公的データとの突合・同期が前提化 | 項目対応関係のメタデータ整備 |
| 政府相互運用性フレームワーク(GIF) | データモデル標準の事実上の指針化 | 社内定義と標準モデルの整合 |
| ワンスオンリー原則 | データ再利用と証跡管理の重要性増大 | リネージと利用目的の可視化 |
さらに、政府相互運用性フレームワーク(GIF)の高度化は、企業システム設計にも長期的な影響を及ぼしています。GIFでは氏名や住所などのコアデータモデルについて、表記ルールや必須項目が厳密に定義されています。SIerや大手企業の間では、将来の官民データ連携や業界横断連携を見据え、社内データ定義をGIFに寄せる動きが広がっています。この際、既存システムとの差分や例外を管理するためにも、データカタログ上での定義管理が不可欠となります。
2025年大阪・関西万博のデータ利活用ガイドラインも、企業実務に強い示唆を残しました。複数主体が関与する環境下で、取得データの分類、利用目的、保存期間をカタログ化し、証跡として残すという考え方は、万博後、スマートシティや大規模プラットフォーム事業に波及しています。関係者の間では、「説明できないデータは持たない」という原則が、事実上のリスク管理基準になりつつあるとの認識が共有されています。
このように政府政策と標準化は、企業に新たな制約を課す一方で、信頼できるデータ流通に参加するための共通言語も提供しています。データカタログは、その接点に立つ実務ツールであり、政策対応コストを抑えつつビジネス価値を引き出すための戦略的インフラとして、2026年の企業データ管理に欠かせない存在となっています。
アクティブメタデータを支える技術アーキテクチャ
アクティブメタデータを支える技術アーキテクチャの本質は、メタデータを静的な管理対象ではなく、リアルタイムに循環し、他システムへ影響を与える実行可能な情報として扱う点にあります。2026年時点の先進的なデータカタログでは、メタデータは保存されるだけでなく、生成・更新・配布・反映までが一連の自動プロセスとして設計されています。
中核となるのが、自動スキャニングとプロファイリングのレイヤーです。SnowflakeやBigQuery、S3といった多様なデータソースに対し、定期的あるいはイベント駆動でスキャンを行い、テーブル定義だけでなく値分布やNULL率、ユニーク性といった統計情報を収集します。これにより、電話番号や個人識別子のような機微情報を高精度で推定し、タグとして即座に反映できます。Alationなど主要ベンダーの公開情報によれば、この自動化により人手によるメタデータ整備工数は大幅に削減されています。
次に重要なのが、クエリログ解析とリネージ生成です。SQLログやETL定義、dbtのマニフェストファイルを解析することで、カラムレベルのリネージを自動生成します。これにより、特定カラムの変更がどのレポートやAIモデルに影響するかを即座に把握できます。ガートナーやAlationの分析でも、インパクト分析の自動化は障害件数と復旧時間を大きく低減する要因とされています。
| アーキテクチャ要素 | 主な役割 | ビジネス効果 |
|---|---|---|
| 自動スキャニング | 構造・内容の把握 | 棚卸しと可視化の高速化 |
| リネージ生成 | 来歴と依存関係の追跡 | 変更影響の即時把握 |
| 双方向同期 | ポリシーの書き戻し | ガバナンスの自動執行 |
アクティブメタデータを特徴づけるもう一つの要素が、双方向同期です。カタログ上で付与されたPIIや機密タグが、データベース側のアクセス制御やマスキング設定に自動反映されます。これは従来の「可視化だけのカタログ」と決定的に異なる点であり、データカタログがガバナンスのコントロールプレーンとして機能する根拠でもあります。N-iXやAlationのトレンド分析でも、この双方向性が分散環境における標準設計として定着しつつあると指摘されています。
さらに、これらのメタデータはナレッジグラフとして内部的に管理されます。データ、ビジネス概念、人、利用実績がグラフ構造で結び付けられることで、生成AIやセマンティック検索が意味理解に基づいた応答を行えるようになります。結果として、アクティブメタデータのアーキテクチャは、単なるデータ管理基盤ではなく、AIの精度とガバナンス信頼性を同時に高めるための技術的背骨として位置付けられています。
データカタログ成熟度モデルで見る組織の現在地
データカタログ成熟度モデルは、組織が現在どの段階に立っているのかを客観的に把握し、次に取るべき一手を見極めるための実践的な物差しとして2026年に定着しています。特に生成AIや分散データ基盤の普及により、単なる整備状況の確認ではなく、経営や業務にどれだけ価値を還元できているかが評価軸になっています。
調査会社Alationやデータマネジメント分野の専門家の整理によれば、国内企業の多くは依然として中間段階に集中しています。**技術メタデータは揃っているが、ビジネス視点での活用や自動化が限定的**という状態です。これは、ツール導入がIT部門主導で進み、業務部門との接続が弱いことが主因だと分析されています。
| 成熟度段階 | 主な特徴 | 2026年時点の到達度感 |
|---|---|---|
| レベル1 | テーブル定義中心、検索用途が限定的 | 脱却期 |
| レベル2 | 用語定義と責任者が明確化 | 最多層 |
| レベル3 | AI自動化とリネージ可視化 | 先進企業層 |
| レベル4 | データが価値として流通 | 一部先行事例 |
成熟度モデルで重要なのは、上位レベルを目指すこと自体ではありません。**自社のビジネス課題に対して、今の段階が本当に適切かを見極める視点**です。例えば規制対応が最優先の金融機関では、レベル2でも十分な価値を発揮します。一方、生成AIを業務に組み込む企業では、レベル3への移行が不可避です。
IDC Japanの分析でも、2026年は「成熟度の段階差」が競争力の差に直結すると指摘されています。特に、アクティブメタデータや自動リネージを導入できている組織は、データ変更時の影響分析やAI学習データの選定速度が大幅に向上しています。
成熟度を正確に測るためには、カタログの機能一覧ではなく、利用実態を見る必要があります。誰が日常業務で参照しているのか、意思決定やAI活用にどれだけ組み込まれているのか。こうした観点で現在地を見定めることが、次の成長段階への最短ルートになります。
日本企業に学ぶデータカタログ導入の実践事例
日本企業におけるデータカタログ導入は、単なるツール導入ではなく、既存アーキテクチャや業務プロセスそのものを変革する取り組みとして進められています。**先進企業の事例に共通するのは、データカタログを意思決定やガバナンスを支える中核インフラとして位置づけている点**です。
代表的な例が株式会社メルカリです。同社はマイクロサービス化の進展により、数百のサービスから生成されるデータの所在や意味が分かりにくくなる課題に直面しました。これに対し、共通データ基盤「DataHub」を構築し、データ生成時点でスキーマとメタデータを必須化しています。データは自己記述的な形式で流通し、カタログと自動連携されるため、分析担当者はデータの来歴や定義を即座に把握できます。**カタログを後付けせず、データパイプラインに組み込む設計思想**が、運用負荷の低減と信頼性向上を両立させています。
リクルートグループの取り組みも示唆に富んでいます。複数事業が並立する同社では、事業ごとに異なる用語定義がデータ活用の障壁となっていました。全社横断のデータカタログ整備にあたり、ビジネス用語の標準化と自動メタデータ収集パイプラインを構築し、エンジニア以外の職種でも検索・理解できる環境を整えています。Alationなどが提唱するデータ民主化の考え方によれば、**非技術者が自律的にデータを発見できることが価値創出の前提**とされており、同社の事例はそれを体現しています。
金融分野では三菱UFJ銀行に代表されるメガバンクが、ガバナンス重視の文脈でデータカタログを活用しています。膨大な業務データに対し、エンドツーエンドのリネージを可視化し、規制当局への報告数値がどのデータから算出されたかを説明可能な状態にしています。これは金融庁対応や内部監査の効率化に直結しており、**データカタログがリスク管理基盤として機能している好例**です。
| 企業 | 主な目的 | 特徴的な活用ポイント |
|---|---|---|
| メルカリ | 分散データの統制 | スキーマ駆動で自動カタログ化 |
| リクルート | 全社データ活用 | 用語標準化とセルフサービス検索 |
| 三菱UFJ銀行 | 規制・監査対応 | リネージによる説明責任の担保 |
これらの事例から明らかなように、日本企業では業種や規模に応じて導入目的は異なるものの、**データカタログを業務に埋め込み、継続的に更新される仕組みとして設計している点**が成果につながっています。ツール選定以上に、既存プロセスとどう結合させるかが成否を分けていると言えるでしょう。
失敗しないための導入・運用ガイドライン
データカタログは導入しただけでは価値を生みません。**失敗を避ける最大のポイントは、導入前から運用までを一つの連続したプロセスとして設計すること**です。ガートナーによれば、データマネジメント施策の多くが成果を出せない理由は、技術選定よりも運用設計と組織定着に起因すると指摘されています。
まず導入フェーズでは、「なぜカタログが必要か」を具体的な業務課題に紐づけることが不可欠です。例えば、分析リードタイムの短縮や生成AIのハルシネーション抑制など、測定可能な目的を設定します。IMARC Groupの調査でも、KPIを設定した企業は、設定しなかった企業に比べROIが約1.5倍高い傾向が示されています。
次に重要なのがスコープ設計です。全社一斉導入は失敗の温床になりがちです。**利用頻度が高く、データ品質の影響がビジネス成果に直結するドメインから始める**ことで、短期間で成功体験を作れます。これはAtlanやAlationが公開している実践ガイドでも共通して推奨されています。
| 観点 | 失敗しやすい例 | 成功しやすい設計 |
|---|---|---|
| 目的 | 検索性向上のみ | 業務KPIと直結 |
| 範囲 | 全社一括 | 特定ドメインから段階展開 |
| 体制 | IT部門のみ | ビジネス部門を含む |
運用フェーズで鍵となるのは自動化です。2026年時点では、アクティブメタデータを前提にした運用が事実上の標準になっています。手動更新に依存したカタログは半年以内に陳腐化するという分析も、Alationのデータマネジメントレポートで示されています。AIによる説明文生成やPII検出を活用し、人は承認と文脈付与に集中すべきです。
また、日常業務への組み込みも欠かせません。BIツールや生成AIの検索インターフェースからカタログを参照させることで、利用は自然に定着します。データアクセス申請をカタログ経由に限定する設計は、ガバナンスと利便性を両立させる実践的な方法として、IDC Japanも評価しています。
最後に避けるべきは完璧主義です。初期段階で網羅性や正確性を追求しすぎると、公開が遅れ価値提供の機会を失います。EPAMの実装調査でも、80%程度の完成度で公開した組織の方が、1年後の利用率と品質が高い結果となっています。データカタログは完成品ではなく、運用によって成熟するインフラであると理解することが、失敗を防ぐ最大のガイドラインです。
人材・組織文化から考えるデータドリブン変革
データドリブン変革を本質的に成功させる鍵は、ツールやアーキテクチャ以上に、人材と組織文化の設計にあります。2026年時点では、多くの企業がデータカタログや生成AIを導入していますが、成果に大きな差が生まれる要因は「人がデータとどう向き合うか」に集約されつつあります。ガートナーやIDCの分析によれば、データ活用プロジェクトの失敗原因の過半は、技術不足ではなく組織的・文化的要因にあると指摘されています。
まず重要なのは、役割と責任の再定義です。従来のIT部門中心の管理モデルでは、データは「管理対象」に留まりがちでした。先進企業では、データを価値創出の単位として捉え、ビジネス部門側に明確なオーナーシップを持たせています。データスチュワードやデータプロダクトマネージャーといった役割が定着し、日常業務の中でメタデータの更新や品質判断が行われる状態が作られています。
データを使う人が、同時にデータの品質と意味に責任を持つ文化が、データドリブン組織の前提条件です。
この文化転換を支えるのが、データリテラシー教育です。2026年には、リクルートや国内金融機関の事例に見られるように、「データの読み方」だけでなく、「データの出所を疑い、文脈を確認する力」を育成する研修が一般化しています。ハーバード・ビジネス・レビューでも、リネージやメタデータを理解する能力が、意思決定の質を左右する重要スキルとして位置付けられています。
特に生成AI時代においては、人材要件も変化しています。AIが分析や要約を担う一方で、人間には結果を解釈し、妥当性を判断する役割が求められます。そのため、分析スキルよりも「問いを立てる力」や「データの前提条件を言語化する力」が評価される傾向が強まっています。
| 観点 | 従来型組織 | データドリブン組織 |
|---|---|---|
| データの所有 | IT部門が集中管理 | ビジネス部門が共同で責任 |
| 意思決定 | 経験と勘が中心 | データと仮説検証が前提 |
| 失敗の扱い | 個人の責任 | 学習機会として共有 |
さらに見逃せないのが、心理的安全性です。データに基づく議論が活発な組織ほど、「数字を出して否定される」ことへの恐怖が少ないとされています。スタンフォード大学の組織研究でも、データ共有が進むチームほど、上司への異論提示が活発になり、結果として業績が向上する相関が示されています。
人材・組織文化の観点から見ると、データドリブン変革とはシステム刷新ではなく、意思決定様式の刷新です。データカタログはその共通言語として機能し、人と人、人とAIをつなぐ媒介となります。技術を導入しただけでは変革は起きませんが、人の行動様式が変わったとき、データは初めて競争力に転換されます。
参考文献
- OvalEdge:Data Catalog Market: Key Trends & Insights for 2026
- Alation:2026 Data Management Trends and What They Mean For You
- IMARC Group:Japan Data Catalog Market Size, Share, Forecast 2026-34
- デジタル庁:Promotion of data strategy
- Atlan:Data Catalog Examples 2026: Real Use Cases and Implementation
- N-iX:Top 11 data management trends for 2026