「社内にデータは山ほどあるのに、ビジネス成果につながらない」──多くの企業が抱えるこの悩みは、2026年の今も変わりません。生成AIや高度な分析基盤が普及する一方で、データ活用の成否を分けているのは、ツールではなく“データの扱い方そのもの”です。
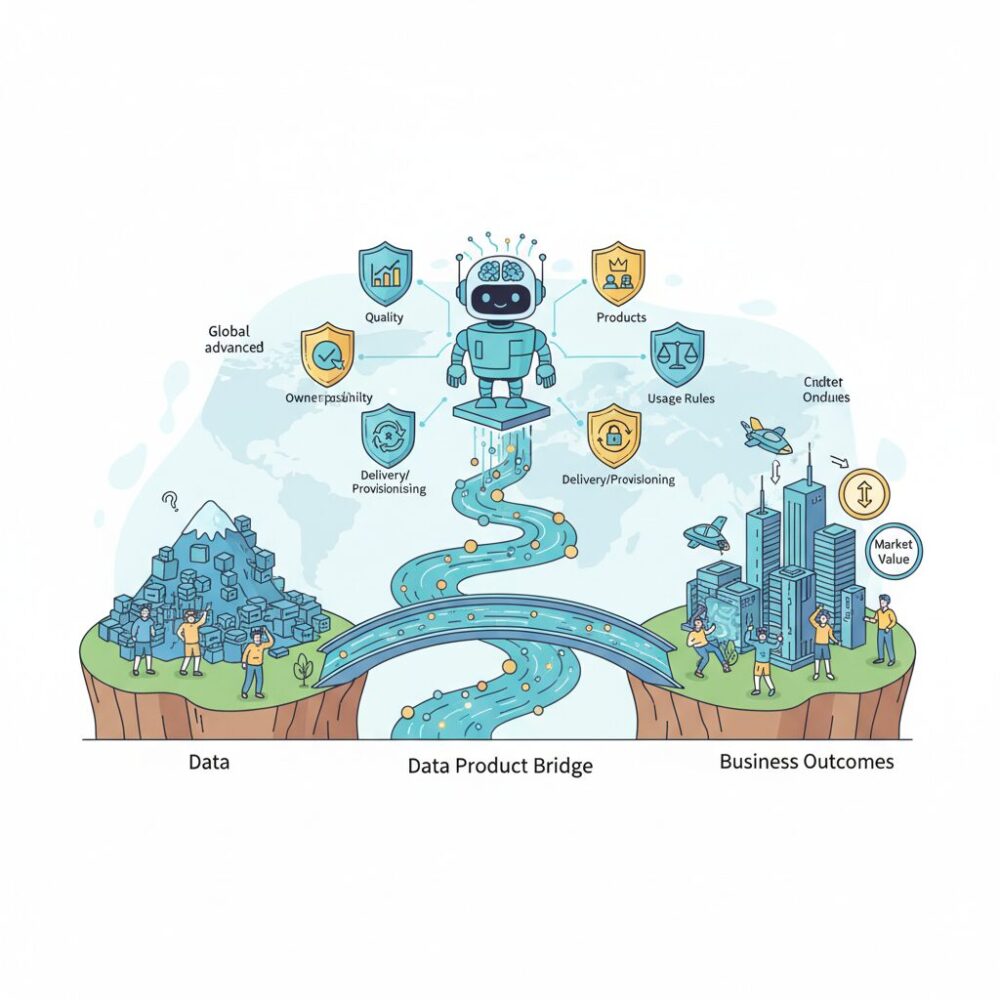
近年、世界の先進企業ではデータを単なる資源ではなく、市場価値を持つ「製品」として設計・管理する考え方が急速に広がっています。品質、責任者、利用ルール、提供方法までを明確にしたデータプロダクトは、AI活用の精度を高めるだけでなく、部門間連携や新規ビジネス創出の基盤にもなっています。
本記事では、2026年時点の最新動向を踏まえ、日本企業がなぜ今データプロダクト化に向き合うべきなのか、その背景にある市場環境、技術進化、組織・人材の変化、そして国内先進事例までを俯瞰します。データ活用を“次の競争力”に変えたい方にとって、全体像と実践のヒントを得られる内容です。
データが「資源」から「製品」へ変わった理由
2026年現在、データが「資源」から「製品」へと位置付けを変えた最大の理由は、収集量そのものが競争優位にならなくなったことにあります。かつてはデータを多く持つ企業が有利だと考えられていましたが、クラウドやSaaSの普及により、データは誰でも比較的容易に集められる存在になりました。その結果、企業価値を分ける要因は、データの量ではなく「使える状態で提供できるかどうか」に移っています。
この変化を象徴するのが、生成AIの本格普及です。IDCによれば、AI投資はデジタル投資全体を大きく上回るペースで拡大しており、AIを業務に組み込む企業が急増しています。しかし、AIは不完全なデータを与えられると、誤った推論やハルシネーションを引き起こします。AIにとって重要なのは、生データではなく、品質・意味・更新責任が明確なデータであり、これが「製品」として管理されたデータでなければならない理由です。
また、データ活用が経営判断や現場オペレーションに直結するようになったことも大きな転換点です。Gartnerが指摘するように、エッジ環境やリアルタイム分析が主流になる中で、毎回個別に加工が必要なデータはスピードの足かせになります。あらかじめ利用者視点で設計され、APIやSLAを備えたデータは、業務部門にとって「すぐ使える完成品」として機能します。
| 観点 | 資源としてのデータ | 製品としてのデータ |
|---|---|---|
| 管理責任 | 不明確、IT部門依存 | 明確なオーナーが存在 |
| 品質保証 | 個別対応、属人化 | SLAやテストで保証 |
| 利用形態 | 都度加工が必要 | そのまま再利用可能 |
さらに重要なのは、データが社内外に流通する対象になった点です。SnowflakeやMicrosoftなどのプラットフォームが示すように、データはコピーせずに共有され、継続的に価値を提供する形へ進化しています。BlackRockの事例が示す通り、データをプロダクトとして提供することで、顧客体験そのものが差別化要因になります。
つまり、データは掘り出して終わりの資源ではなく、設計・製造・品質管理・改善を繰り返す対象になりました。継続的に価値を生み続ける存在へと性質が変わったことこそが、データが「資源」から「製品」へと変わった本質的な理由なのです。
2026年におけるデータプロダクトの定義と必須要素

2026年におけるデータプロダクトは、単なるデータセットや分析用データベースを指す言葉ではありません。現在の主流な定義は、特定のビジネス価値を継続的に提供することを目的として設計され、品質・責任・利用方法が明確に定義されたデータとその付随機能の集合体です。GartnerやAlationなどの調査機関によれば、データを「管理対象」ではなく「顧客に提供する製品」として扱う企業ほど、AI活用のROIが高い傾向が確認されています。
この定義が重要視される背景には、生成AIの本格普及があります。IDCの分析では、AIプロジェクト失敗の主要因の6割以上がデータ品質と文脈不足に起因するとされており、曖昧なデータ基盤ではAIが正しい価値を生みません。そのため2026年現在、データは「使えるかどうか」ではなく「製品として信頼できるか」が問われる段階に入っています。
| 観点 | 従来のデータ管理 | 2026年のデータプロダクト |
|---|---|---|
| 位置づけ | 業務の副産物 | 独立した製品 |
| 責任主体 | IT部門 | ビジネスドメイン |
| 利用方法 | 個別依頼・属人化 | セルフサービス |
データプロダクトを成立させるためには、いくつかの必須要素が揃っている必要があります。第一にデータ本体です。これは構造化・非構造化を問いませんが、ビジネス目的に直結していることが前提です。第二にメタデータで、データの意味、生成元、更新頻度、制約条件などが自己記述的に整理されていなければなりません。BlackRockの事例では、メタデータ整備後にデータ探索時間が約40%短縮したと報告されています。
第三に不可欠なのが標準化されたアクセス手段です。SQLエンドポイントやAPIを通じ、利用者が生成プロセスを意識せずに安全に利用できることが求められます。第四に品質保証と契約の概念があります。SLAやデータ鮮度、欠損率といった指標が明示されて初めて、ビジネス判断に耐えるプロダクトとなります。これは製造業における品質保証書と同じ役割を果たします。
さらに2026年の特徴として、コードとインフラもプロダクトの一部として管理される点が挙げられます。dbtやInfrastructure as Codeの普及により、変換ロジックや実行環境が再現可能な形で管理され、属人性が排除されています。こうした要素が一体となることで、データプロダクトは初めて「再利用可能で拡張可能な経営資産」となり、日本企業における競争力の源泉として機能し始めています。
FAIR原則はビジネスでどう進化したのか
FAIR原則はもともと学術データ共有のために提唱された考え方ですが、2026年のビジネス現場では、その解釈と実装が大きく進化しています。最大の変化は、FAIRが「理想論」ではなく、事業価値を生むための実務要件として再定義された点です。データを探せる、使える、つながる、再利用できるという性質は、もはや研究効率の話ではなく、AI活用や意思決定スピードを左右する競争条件になっています。
特に注目すべきは、FAIR各要素がテクノロジーと組織設計の両面で具体化されたことです。たとえばFindableは、単なるメタデータ登録ではなく、生成AIを組み込んだエンタープライズデータカタログによって実装されています。GartnerやAlationの分析によれば、自然言語検索と利用履歴解析を組み合わせたカタログを導入した企業では、データ探索にかかる時間が平均で30〜40%短縮されています。
Accessibleも同様に進化しました。従来は「アクセスできるかどうか」が焦点でしたが、現在は誰が、どの条件で、どの目的なら即座に使えるかまでが設計対象です。Snowflakeのセキュアデータシェアリングのように、データをコピーせず権限だけを付与する仕組みは、セキュリティとスピードを両立させ、金融・製造といった規制産業でもFAIRを現実解にしました。
| FAIR要素 | 従来の解釈 | 2026年のビジネス実装 |
|---|---|---|
| Findable | カタログに載っている | AI検索で業務文脈から即発見 |
| Accessible | 技術的に接続可能 | 契約・権限が自動適用され即利用 |
| Interoperable | 形式が統一されている | 部門横断で意味的に結合可能 |
| Reusable | 再利用してもよい | 再利用される前提で設計・評価 |
Interoperableの進化も実践的です。商品コードや顧客IDといった共通キーの整備に加え、業界標準のセマンティクスを採用する動きが広がっています。IDCは、相互運用性を意識したデータ設計を行う企業ほど、部門横断分析や生成AIのRAG精度が高いと指摘しています。これはFAIRがAI品質そのものに直結していることを示しています。
そして最も重要なのがReusableです。再利用可能性は、ROIの最大化を意味します。BlackRockの事例では、データプロダクトごとに利用回数とビジネス貢献を可視化し、再利用頻度が高いデータほど追加投資する仕組みを導入しています。FAIRはここで品質指標から経営指標へと役割を変えました。
このように2026年のFAIR原則は、データガバナンスのチェックリストではなく、データを製品として育て、AIとビジネスを加速させるための設計思想へと進化しています。FAIRを満たすかどうかは、データが価値を生み続けるかどうかを判断する、極めて現実的な基準になっています。
生成AI時代にデータプロダクトが不可欠な背景
生成AIがビジネスの現場に深く浸透した2026年において、データプロダクトが不可欠とされる最大の背景は、AIの価値がアルゴリズムではなくデータ品質によって決定される段階に入ったことにあります。大規模言語モデルそのものは汎用化が進み、企業間の競争優位は「何を学習・参照させているか」に急速に移っています。
IDCによれば、AI投資は全体のデジタル投資よりも1.7倍速く成長しており、特に生成AIは経営判断や業務自動化の中枢を担う存在になりました。しかし、社内データが断片化され、意味や品質が保証されていない状態では、RAGなどの高度なAI活用は成立しません。ここで求められるのが、信頼性・再利用性・責任範囲が明確化されたデータプロダクトです。
従来のデータ活用では、分析のたびに個別最適でデータ加工が行われ、同じ指標が部署ごとに異なる定義で使われることが常態化していました。生成AI時代においてこれは致命的です。AIは人間のように文脈の違いを察することができず、曖昧なデータを与えれば誤った推論を量産します。Gartnerが指摘するように、AIリスク管理の本質はモデルよりもデータガバナンスにあります。
| 従来のデータ活用 | 生成AI時代の要件 |
|---|---|
| プロジェクト単位で一時的に利用 | 継続的に利用される製品として管理 |
| 担当者依存の暗黙知 | メタデータによる明示的な知識化 |
| 品質責任が不明確 | オーナーとSLAが明確 |
また、エッジコンピューティングとIoTの普及も背景として見逃せません。Gartnerの予測では、2026年までにエッジ展開の半数に機械学習が組み込まれるとされています。現場で発生する膨大なデータをすべて中央に集約するのではなく、意味のある形に要約・構造化して流通させる必要があり、その単位としてデータプロダクトが最適化されています。
さらに、日本企業特有の事情も影響しています。人手不足が深刻化する中、暗黙知に依存した業務運営は限界を迎えています。経済産業省やJDMCの議論でも、データを個人や部署に属するものではなく、組織全体で再利用可能な資産として扱う重要性が繰り返し指摘されています。データプロダクトは、この課題に対する実装レベルでの解答です。
生成AIは「問いに答える存在」ですが、データプロダクトは「問いの前提を整える存在」です。前提が整っていなければ、どれほど高度なAIであっても誤った意思決定を導きかねません。だからこそ2026年の現在、データプロダクトは単なるデータ管理手法ではなく、AI時代の経営インフラとして不可欠な位置づけを与えられているのです。
データメッシュとデータファブリックの融合トレンド
2026年現在、データメッシュとデータファブリックは対立概念ではなく、相互補完的に融合する前提アーキテクチャとして語られるようになっています。AlationやGartnerの分析によれば、現場主導のデータオーナーシップと、全社横断の自動化・可視化を両立できる点が評価され、ハイブリッドモデルが事実上の標準となりつつあります。
背景にあるのは、生成AIの本格活用によって、データの意味的整合性と即時利用性の両方が同時に求められるようになった点です。思想としてはメッシュ、実装としてはファブリックという整理が浸透し、ビジネス部門が責任を持つデータプロダクトを、技術基盤が自動的に束ねる構造が現実解になっています。
| 観点 | データメッシュ | データファブリック |
|---|---|---|
| 主軸 | 組織・責任分散 | 技術・自動化 |
| 強み | 業務文脈の正確性 | 横断的可視化と統制 |
| 融合後の役割 | データプロダクトの所有 | ガバナンスと連携基盤 |
この融合が重要なのは、単なる設計論ではなく運用コストとスピードの最適化に直結するからです。純粋なメッシュではドメイン間の重複や品質ばらつきが問題になりやすく、純粋なファブリックではビジネス文脈が希薄になります。両者を組み合わせることで、品質責任は現場に残しつつ、メタデータ収集やポリシー適用はAIが担う分業が成立します。
実際、日本企業でもこの流れは顕著です。キリンホールディングスでは、事業部門が生成するデータをメッシュ的に管理しながら、全社共通のデータカタログとアクセス制御をファブリック基盤で統合しています。同社の取り組みは、AIが参照するデータの信頼性を担保するには、組織と技術の両輪が不可欠であることを示しています。
また、Microsoft FabricやSnowflakeの進化も融合を後押ししています。これらのプラットフォームは、分散したデータプロダクトを前提にしつつ、リネージュ追跡や品質チェックを自動化する機能を標準搭載しています。IDCやGartnerが指摘するように、アーキテクチャ選択の議論は終わり、組み合わせ方の成熟度が競争力を左右する段階に入っています。
今後は、この融合モデルを前提に、どこまで自社の業務プロセスに適合させられるかが問われます。重要なのは流行語として採用することではなく、データプロダクトの責任境界と自動化範囲を明確に設計し、AI時代に耐えうる持続的なデータ基盤を築くことです。
日本市場における経済インパクトと規制環境の変化
日本市場においてデータプロダクト化がもたらす経済インパクトは、もはやIT部門の効率化にとどまらず、産業構造そのものに影響を与える段階に入っています。IDC Japanの予測によれば、国内IT市場は2028年に30兆円規模へ拡大し、その成長を最も強く牽引しているのがデータ基盤、AI、分析系ソフトウェアへの投資です。**データを製品として設計・流通させる企業ほど、投資対効果が明確になり、経営判断のスピードと精度が同時に高まっています。**
特に注目すべきは、データプロダクト化が新たな収益源を生み始めている点です。製造業では稼働データを外販用の分析サービスとして提供し、金融業では匿名化・統計化された取引データを付加価値情報として顧客に還元する動きが広がっています。関西電力がデータ活用により年間約300億円規模の価値創出を実現した事例は、データがコストセンターからプロフィットセンターへ転換し得ることを示す象徴的なケースです。
| 市場区分 | 2025年規模 | 2028年見通し | 主な成長要因 |
|---|---|---|---|
| 国内IT市場全体 | 約26.6兆円 | 約30.2兆円 | DX全社展開、AI実装 |
| 企業向けソフトウェア | 3兆円超 | 4兆円超 | データ基盤・分析需要 |
こうした経済効果を後押ししているのが、規制環境の変化です。個人情報保護法は3年ごとの見直しに基づき、2025年以降「保護と利活用の両立」をより強く意識した運用へと舵を切りつつあります。専門家の解説によれば、統計作成や公益性の高い用途においては、一定条件下で本人同意を不要とする整理が進み、企業間・産学連携でのデータ流通が現実的になっています。
一方で、規制が緩む分だけガバナンス要求は厳格化しています。課徴金制度の議論やAI事業者ガイドラインの改定は、**「管理されていない生データは流通させない」という強いメッセージ**でもあります。データをプロダクトとして設計し、利用目的、品質基準、アクセス制御を明示した上で提供することが、規制対応そのものを効率化する手段になっています。
欧州のGDPRのような一律・強制型規制とは異なり、日本はガイドラインと自主的取り組みを重視する傾向が強いとされています。この特徴は、日本企業にとって不利ではなく、むしろ**ガバナンスを組み込んだデータプロダクトを競争力として磨き上げる余地が大きい**ことを意味します。経済的リターンと規制適合を同時に達成できるかどうかが、2026年以降の日本企業の明暗を分ける重要な分岐点になっています。
日本企業が直面する組織サイロと文化的課題
日本企業がデータプロダクト化を進める際、技術以上に深刻な障壁となるのが組織サイロと文化的課題です。事業部制を長年採用してきた大企業ほど、組織ごとにKPI、人事評価、予算管理が最適化されており、データは部門内の成果を守るための資源として囲い込まれがちです。**この構造では、データを全社横断で再利用する前提そのものが成立しません。**
実際、IDC JapanやGartnerの日本企業調査でも、データ活用が進まない要因として「部門間連携の欠如」「データ所有権が不明確」が繰り返し指摘されています。欧米企業では職務ベースで人材が流動化する一方、日本では長期雇用を前提に専門性が部門内に閉じやすく、「他部門のためにデータを整備する」インセンティブが働きにくいのが現実です。
| 観点 | 従来型日本企業 | データプロダクト前提 |
|---|---|---|
| データの位置づけ | 部門成果の副産物 | 全社価値を生む製品 |
| 責任所在 | IT部門・ベンダー | 業務ドメイン自身 |
| 評価軸 | 部門最適KPI | 横断的利用価値 |
文化面で特に根深いのが「失敗回避志向」です。データを公開し品質問題が露呈すると評価が下がるのではないかという恐れが、結果としてデータ共有を妨げます。MIT Sloan Management Reviewでも、データドリブン組織への移行には心理的安全性の確保が不可欠だと指摘されています。**品質問題を個人や部門の責任に帰す文化では、データは決してプロダクトになりません。**
先進事例を見ると、成功企業は例外なく評価制度とガバナンスを同時に変えています。関西電力では、データ品質の改善や他部門での再利用実績を正式な業績評価に組み込みました。キリンホールディングスも、生成AIの精度低下を「データ提供側の課題」と可視化することで、現場が自らデータ整備に向かう構造を作っています。
組織サイロの解消は「連携を呼びかける」ことでは達成できません。評価、権限、責任の設計を変え、データを共有した方が得をする構造を作ることが唯一の解決策です。
データプロダクト化は、IT施策ではなく経営変革です。縦割り組織と調和を重んじる日本的文化を前提にしつつ、どこまで意図的に摩擦を生み出せるかが、2026年以降の競争力を左右します。
データプロダクトマネージャーという新しい中核人材
2026年現在、データプロダクト化を本気で推進する企業において、最も重要な中核人材として位置付けられているのがデータプロダクトマネージャーです。この役割は、単なるデータ活用担当やIT企画職の延長ではありません。データを一つの製品として定義し、価値を生み続ける責任を負う、いわば「データ版のミニCEO」としての機能が求められています。
従来の日本企業では、データエンジニアが基盤を構築し、データサイエンティストが分析を行う分業体制が一般的でした。しかしこの体制では、「そのデータは誰のために存在し、どのKPIに貢献し、いつまで価値を出し続けるのか」という問いが宙に浮きがちでした。データプロダクトマネージャーは、この空白を埋めるために誕生した職種です。
具体的には、社内外のユーザー要求を起点にデータプロダクトのビジョンを定義し、優先順位を付けたロードマップを描き、品質やSLA、ROIに最終責任を持ちます。Visaやジョンソン・エンド・ジョンソンの公開ジョブディスクリプションによれば、データPdMはビジネス部門、エンジニアリング、ガバナンス部門を横断的につなぐ調整役であり、成果指標として「利用率」や「再利用回数」が明確に設定されています。
| 観点 | 従来の役割 | データプロダクトマネージャー |
|---|---|---|
| 責任範囲 | プロジェクト完了まで | ライフサイクル全体 |
| 成果指標 | 納期・要件充足 | ROI・利用定着 |
| 視点 | 内部最適 | ユーザー価値起点 |
また、2026年の特徴として、生成AIとの接続を前提とした設計力が必須スキルになっています。RAGを活用する場合、どのデータを「信頼できる参照元」としてAIに与えるのかを判断するのはデータPdMの役割です。GartnerやProduct Schoolが指摘するように、ここを誤るとハルシネーションが経営リスクに直結します。
人材市場においても、その希少性は数値に表れています。国内求人では年収800万〜1,000万円台が中心で、外資系や先進企業では1,500万円超の提示も珍しくありません。これは単なる人件費高騰ではなく、データを事業資産として扱える人材への戦略的投資と見るべきです。
データプロダクトマネージャーの台頭は、日本企業が「作ったら終わり」のプロジェクト文化から脱却し、継続的に価値を生むデータ経営へ移行している明確なサインです。この職種を中心に据えられるかどうかが、2026年以降の競争力を大きく左右します。
関西電力・キリンに学ぶ国内先進事例の要点
関西電力とキリンホールディングスの事例は、データプロダクト化が単なるIT施策ではなく、経営価値そのものを生み出す仕組みであることを示しています。両社に共通するのは、データを現場の副産物として扱うのではなく、明確なオーナーと目的を持つ「製品」として再定義した点です。
関西電力は、日本データマネジメント・コンソーシアムが公表した情報によれば、全社的なデータマネジメント高度化により2024年度単体で約300億円規模の価値創出を実現しました。発電・送配電といったインフラ領域では、設備トラブルの未然防止や需給予測精度の向上が収益やコスト構造に直結します。同社はセンサーデータや運転データをデータプロダクトとして整備し、予知保全や燃料調達最適化といった意思決定に即座に使える状態を作りました。
特筆すべきは、データ品質管理を一過性のプロジェクトにせず、業務として定着させた点です。現場部門がデータの意味や精度に責任を持ち、IT部門は基盤とガバナンスを支える役割に徹しました。この分業により、AI活用を前提とした信頼性の高いデータ供給が可能になっています。
| 企業 | 主な狙い | データプロダクト化の要点 |
|---|---|---|
| 関西電力 | 収益性・安定供給の両立 | 現場起点での運転・設備データの製品化と継続管理 |
| キリンHD | 知的資産の全社活用 | 生成AIとデータメッシュを連動させた責任分散 |
一方、キリンホールディングスは、独自の生成AI「BuddyAI」を軸にデータプロダクト化を推進しています。EnterpriseZineなどの報道によれば、同社はデータメッシュの考え方を採用し、醸造、営業、SCMといった各ドメインが自らのデータに責任を持つ体制を構築しました。AIに正しい答えを出させるためには、参照元データが正しくなければならないというメッセージが、現場の当事者意識を強く刺激しています。
このアプローチの本質は、テクノロジー導入を目的化しなかった点にあります。BuddyAIは単なる業務効率化ツールではなく、暗黙知の形式知化や技術継承を支える存在です。生成AIの精度を担保するために、各部門が自らデータ定義や更新頻度を見直し、結果としてデータプロダクトの再利用性が高まりました。
両社の事例から導かれる要点は明確です。第一に、データプロダクトの価値はP/Lにどう影響するかで測られていること。第二に、IT部門任せではなく、データを生む現場が責任主体になっていること。第三に、AI活用はデータ品質を引き上げる強力な触媒として機能することです。関西電力とキリンは、業種は異なれど、データを製品として扱う覚悟が競争力を生んでいる好例だと言えます。
2026年以降を見据えた日本企業への戦略的示唆
2026年以降を見据えた日本企業への最大の示唆は、データプロダクト化を「IT施策」ではなく「経営モデルの再設計」として捉える必要がある点にあります。生成AIが標準装備となった現在、競争優位の源泉はアルゴリズムそのものではなく、どのような品質のデータを、どの速度と統制で供給できるかに移行しています。IDCが示すように、AI投資は全体IT投資の1.7倍の成長率で拡大していますが、成果を上げている企業は例外なくデータプロダクトを前提とした経営判断を行っています。
特に日本企業にとって重要なのは、データプロダクトを「内製の共通言語」に変えることです。従来の日本型組織では、部門ごとにKPIやデータ定義が異なり、全社最適を阻害してきました。しかし、データプロダクトという単位で品質、SLA、利用条件を明示することで、部門間の暗黙知は形式知へと変換されます。Gartnerが提唱するPolicy as Codeの考え方は、こうした共通言語を自動的に運用する基盤として現実解になりつつあります。
| 視点 | 従来型 | データプロダクト前提 |
|---|---|---|
| 意思決定 | 部門最適・経験依存 | 全社横断・データ基準 |
| AI活用 | PoC中心 | 業務組み込み型 |
| 投資評価 | システム完成がゴール | 継続ROIで評価 |
もう一つの戦略的示唆は、データプロダクトを外部価値に転換できる企業が新たな収益源を獲得する点です。個人情報保護法の見直し議論が進む中、匿名加工や統計化を前提としたデータ提供は現実的なビジネスになりつつあります。BlackRockの事例が示すように、社内向けに整備したデータプロダクトが、そのまま顧客向けサービスに転用されるケースは今後日本でも増えると考えられます。
加えて、日本企業は人材戦略を根本から見直す必要があります。データプロダクトマネージャーの市場価値が急騰している背景には、データをP/Lに結びつけられる人材が極端に不足している現実があります。年功序列的な処遇のままでは、こうした人材を惹きつけることは困難です。関西電力やキリンホールディングスの事例が示す通り、経営直結の権限と評価を与えることが、データ文化定着の近道になります。
最後に重要なのは、完璧を目指さない姿勢です。2026年以降の環境では、全社一斉導入よりも、高価値ユースケースから始めて学習速度を高める企業が勝ちます。データプロダクトは作って終わりではなく、使われ続けて初めて価値を生みます。継続的に改善される前提で経営資源を配分できるかどうかが、日本企業の将来を分ける分水嶺になるでしょう。
参考文献
- Alation:Data Fabric vs. Data Mesh: 2026 Guide to Modern Data Architecture
- IDC:IDC Predicts AI Spending Will Grow 1.7x Faster Than Overall Digital Tech Investments
- IT Leaders:JDMCが「2025年データマネジメント賞」を発表、大賞の関西電力はDX/データ活用で300億円の価値創出
- EnterpriseZine:キリンはAI時代を『データメッシュ』で戦う 独自生成AIの活用拡大
- Snowflake:三菱UFJ信託銀行グループのSnowflake導入活用事例
- Atlan:Gartner Data Mesh 2026: Hype Cycle Analysis & Setup Guide