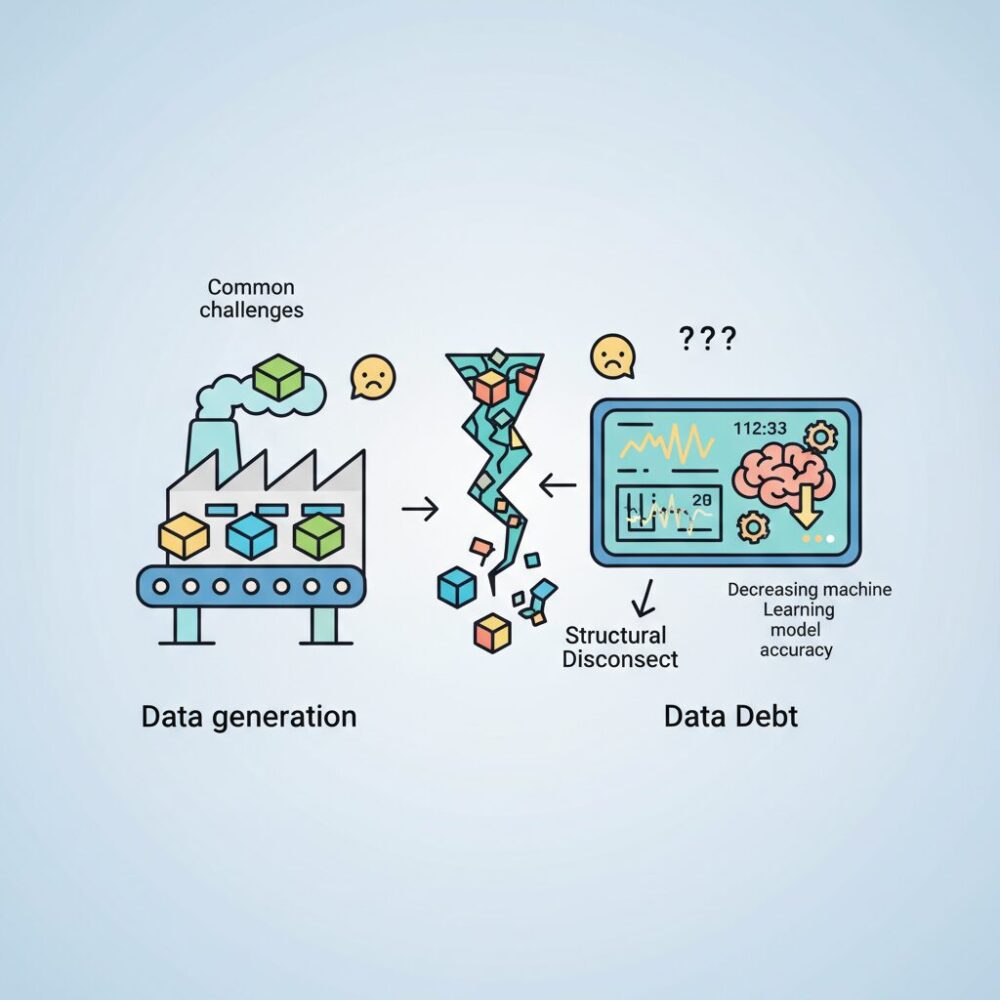
データ活用が企業競争力を左右する時代において、「データの信頼性」をどう担保するかは多くの組織が直面する共通課題です。ダッシュボードの数値が突然変わる、機械学習モデルの精度が理由も分からず低下する、そんな経験をお持ちの方も多いのではないでしょうか。
こうした問題の背景には、データ生成側と利用側の間にある構造的な断絶、いわゆるデータ負債の存在があります。2026年現在、この課題に対する現実的かつ体系的な解として注目を集めているのが「データコントラクト」です。これは単なるドキュメントではなく、API契約のように技術的に強制可能な仕組みとして、エンタープライズのデータ基盤に深く組み込まれつつあります。
本記事では、データコントラクトの定義や構造、標準化動向、主要ツール、そしてROIや実装事例までを俯瞰します。さらに、生成AIやRAGの普及によって重要性が増すセマンティック・データコントラクトや、日本企業における導入の勘所にも触れます。読み終えたとき、なぜ今データコントラクトが不可欠なのか、そして自社でどう活かすべきかが明確になるはずです。
2026年におけるデータエンジニアリングの変化とデータコントラクトの必然性
2026年のデータエンジニアリングは、単なる技術スタックの進化ではなく、データの扱い方そのものが構造的に変わった点に本質があります。マイクロサービス化とクラウドネイティブ化が進んだ結果、データ生成元の変更頻度は飛躍的に高まりました。一方で、その影響を受ける分析基盤やAIシステムは複雑化し、些細なスキーマ変更が経営判断や顧客体験に直結するリスクを抱えています。
Splunkが示す2026年のデータトレンド分析によれば、企業の重大なデータ障害の多くは下流ではなく上流の仕様変更に起因しています。この構造的問題に対し、従来の「後追いで品質を監視する」手法は限界を迎えました。そこで主流となったのが、品質責任をデータ発生源に移すシフトレフトの考え方であり、その実装手段としてデータコントラクトが不可欠になっています。
データコントラクトは、単なるドキュメントではありません。API契約と同様に、機械的に検証され、破られればデプロイ自体が止まる前提で設計されます。Chad Sandersonが提唱する「Data as a Product」の思想では、データは排出物ではなく製品であり、仕様と保証を持つべきだとされています。この思想が2026年に現実解として定着した背景には、AI活用の本格化があります。
| 観点 | 従来型データ基盤 | 2026年型アプローチ |
|---|---|---|
| 品質担保の位置 | 下流での検知と修正 | 上流での事前強制 |
| 変更管理 | 暗黙知と属人対応 | 契約として明示・自動検証 |
| AIへの影響 | 誤学習や幻覚が発生 | 信頼可能な入力を保証 |
特に生成AIやRAGを業務に組み込む企業では、データの意味や鮮度がモデル精度を左右します。意味が曖昧なまま流通するデータは、AIにとってノイズでしかありません。データコントラクトは、構造だけでなく意味と期待値を固定する役割を担い、AI時代の前提条件となりました。
この変化は、データエンジニアの役割も変えています。ETLの最適化や基盤運用に留まらず、プロデューサーとコンシューマーの合意を技術で担保する設計者へと進化しています。2026年においてデータコントラクトが必然となった理由は、技術流行ではなく、ビジネスとAIを安全につなぐ唯一の現実的手段だからに他なりません。
データ負債とデータダウンタイムが経営に与える影響

データ負債とデータダウンタイムは、IT部門だけの技術課題ではなく、経営判断の質とスピードを直接的に損なう経営リスクとして認識されています。2026年現在、多くの企業がデータドリブン経営や生成AI活用を掲げる一方で、**基盤となるデータの信頼性が低いままでは、意思決定そのものが不安定化する**という現実に直面しています。
Splunkのデータトレンド分析によれば、データパイプラインの障害や品質劣化によって発生するデータダウンタイムは、単なるレポート遅延にとどまらず、売上予測の誤り、在庫最適化の失敗、マーケティング投資判断の先送りなど、経営レベルの判断ミスへと波及しやすいと指摘されています。特にリアルタイム性が求められる業界ほど、その影響は指数関数的に拡大します。
データ負債の厄介な点は、財務諸表のように可視化されないまま蓄積することです。Chad Sandersonが提唱するData as a Productの文脈では、仕様が曖昧なデータや、責任者が不明確なデータは、将来必ず修正コストとして跳ね返るとされています。**短期的な開発スピードを優先した結果、後工程で何倍もの工数と意思決定遅延を生む構造**が、データ負債の本質です。
| 観点 | 影響内容 | 経営への波及 |
|---|---|---|
| データダウンタイム | ダッシュボード停止、数値異常 | 意思決定の遅延・機会損失 |
| データ負債 | 手作業修正、属人化対応 | 運用コスト増大・人材疲弊 |
| 信頼性低下 | 数値への不信感 | 勘と経験への逆戻り |
Monte Carloなどのデータオブザーバビリティ企業の分析では、経営層が「この数字は正しいのか」という確認に時間を費やし始めた瞬間、組織の意思決定速度は大きく低下するとされています。**データを疑う文化が定着すると、データ活用のROIは急激に下がる**という点は、多くの企業事例に共通しています。
さらに2026年の特徴として、生成AIやRAGシステムへの影響が無視できません。品質の担保されていないデータがAIに入力されると、もっともらしい誤答が高速で量産されます。これは単なる業務効率低下ではなく、誤った経営判断を強く後押ししてしまう点で、従来以上に危険です。研究者や実務家の間では、**データダウンタイムはAI時代において経営ダウンタイムに直結する**という認識が広がっています。
結果として、データ負債とデータダウンタイムは、売上やコストといった定量指標だけでなく、意思決定への信頼、組織のアジリティ、人材の創造性といった無形資産を静かに毀損します。経営インフラとしてのデータをどう扱うかが、企業価値の中長期的な差を生む局面に入っていると言えるでしょう。
データコントラクトの定義と基本コンセプト
データコントラクトとは、データの提供者と利用者の間で交わされる、データに関する明示的かつ拘束力のある取り決めを指します。2026年時点では、単なる運用上の合意やドキュメントではなく、ソフトウェアエンジニアリングにおけるAPI契約と同様に、機械的に検証・強制される前提で設計される点が最大の特徴です。AtlanやLinux Foundation配下のBitolプロジェクトの整理によれば、データコントラクトは人が読む仕様書であると同時に、CI/CDパイプライン上で自動チェックされるコードとして存在します。
この概念が注目される背景には、データ基盤の複雑化があります。マイクロサービス化した業務システムでは、上流の小さなスキーマ変更が下流の分析やAIモデルに深刻な影響を与えるケースが頻発してきました。Splunkのデータトレンド分析でも、こうした変更起因のデータ障害が意思決定の遅延や信頼低下を招くことが指摘されています。データコントラクトは、この断絶を事前に防ぐための「予防線」として機能します。
基本コンセプトを理解するうえで重要なのは、データを「副産物」ではなく製品として扱う視点です。Chad Sandersonが提唱したData as a Productの考え方では、データにも仕様、品質保証、サポート責任が求められます。データコントラクトはその仕様書に相当し、何が提供され、何が保証され、どこまでが責任範囲なのかを明確にします。
| 観点 | 従来のデータ共有 | データコントラクト |
|---|---|---|
| 合意の形式 | 暗黙的・口頭中心 | 明示的・コード化 |
| 変更時の検知 | 事後的 | 事前検証 |
| 品質責任 | 下流依存 | 上流で担保 |
もう一つの重要なポイントは、データコントラクトがスキーマ定義に限定されない点です。2026年の標準的な定義では、構造だけでなく、ビジネス上の意味、鮮度や可用性といったサービスレベル、さらにはセキュリティや利用制約まで含めて契約対象となります。Bitolが公開するOpen Data Contract Standardでも、この多層的な構造が前提とされています。
これにより、データ利用者は「どのような意味で定義された数値なのか」「どの程度の遅延や欠損が許容されるのか」を事前に理解できます。一方、提供者側も、契約範囲外の期待を背負わずに済みます。期待値のズレを構造的に排除することこそが、データコントラクトの本質的な価値だと言えるでしょう。
専門家の間では、データコントラクトはガバナンス強化のための制約ではなく、むしろ開発速度を守るための仕組みだと位置付けられています。変更の影響を事前に可視化し、自動的に検証できる状態を作ることで、安心して改善を重ねられる基盤が整います。この「安全に速く動く」ための思想が、データコントラクトの基本コンセプトを支えています。
スキーマ・セマンティクス・SLA・ポリシーという四層構造
スキーマ・セマンティクス・SLA・ポリシーという四層構造は、2026年時点のデータコントラクトを理解する上で中核となる設計思想です。重要なのは、これらが単なるチェック項目の集合ではなく、データを「技術資産」から「契約されたプロダクト」へ昇華させるための役割分担として機能している点です。
まずスキーマ層は、最も技術的で形式的な基盤です。カラム名、型、Null制約、Enumといった構造定義は、ProtobufやAvroとの互換性を前提に記述され、CI/CD上で機械的に検証されます。ここで重要なのは、網羅性よりも安定性です。内部実装の詳細ではなく、外部に公開しても変更頻度が低いインターフェースだけを定義することで、変更耐性が大きく向上します。
次にセマンティクス層は、2026年に最も注目されている進化ポイントです。同じ「revenue」というカラムでも、税抜きか税込みか、返品を含むか否かで意味は全く異なります。GartnerやAtlanの分析によれば、データ品質問題の多くは構造ではなく意味の誤解に起因するとされています。セマンティクスは人間とAIの双方が誤解しないための共通言語であり、生成AIやRAGシステムにおいては特に不可欠です。
| レイヤー | 主な目的 | 2026年の実務的価値 |
|---|---|---|
| スキーマ | 構造の安定化 | デプロイ前検証と破壊的変更の防止 |
| セマンティクス | 意味の統一 | AIの誤解と組織内解釈ズレの防止 |
| SLA | 品質の定量化 | ビジネス影響の可視化と優先順位付け |
| ポリシー | 統制と責任 | ガバナンスと自動化の接続点 |
SLA層は、データをIT指標ではなくビジネス指標として扱うための装置です。FreshnessやCompletenessを数値で定義することで、「遅れている」「欠けている」という曖昧な議論が排除されます。Monte Carloなどのツールでは、このSLAを基準に影響範囲を即座に特定でき、障害対応が属人的判断から契約ベースの判断へと変化しています。
最後のポリシー層は、四層構造の中で最も経営に近いレイヤーです。データオーナー、PII区分、保持期間、利用制限といった情報は、法務・セキュリティ・FinOpsと直結します。Linux Foundation傘下のODCSがこの層を重視している背景には、ガバナンスを人手ではなくコードで実装するという潮流があります。ポリシーがコード化されて初めて、スケール可能な統制が成立します。
四層構造の本質的な価値は、どれか一層が欠けると全体が機能不全に陥る点にあります。スキーマだけでは意味が守れず、セマンティクスだけでは品質が測れず、SLAだけでは責任が曖昧になり、ポリシーだけでは現場が動きません。この分業と連携こそが、2026年のエンタープライズ・データガバナンスを支える実装原理です。
実装で陥りやすいアンチパターンと失敗要因
データコントラクトの導入が広がる一方で、2026年時点でも失敗事例は後を絶ちません。その多くは技術不足ではなく、設計思想や運用前提の誤りに起因しています。特に注意すべきなのは、データコントラクトを「静的な文書」として扱ってしまうことです。Linux Foundation配下のBitolプロジェクト関係者も指摘している通り、強制力を持たないコントラクトは時間とともに更新されなくなり、結果として実装と乖離した“化石化した仕様書”になります。
このアンチパターンは、ガバナンス強化を目的に導入したはずのデータコントラクトが、逆に開発スピードを落とす官僚的プロセスへと変質する点に本質的な問題があります。CI/CDと連動せず、違反しても処理が止まらない設計では、プロデューサー側に品質担保のインセンティブが働きません。その結果、下流での検知と修正が常態化し、Splunkが示すデータダウンタイム削減という本来の効果が得られなくなります。
次に多い失敗が、過度に網羅的なスキーマ設計です。内部実装の都合や将来利用を想定して、不要なカラムや生データをそのまま契約に含めてしまうケースが散見されます。Atlanの分析によれば、コントラクトの肥大化はプロデューサーの変更自由度を著しく制限し、結果として非公式な迂回データやシャドーパイプラインを生む原因になります。データコントラクトは「安定した公開インターフェース」を定義するものであり、内部構造の完全な写像ではありません。
| アンチパターン | 短期的影響 | 中長期的リスク |
|---|---|---|
| 強制力のない文書運用 | 導入初期は混乱が少ない | 形骸化と品質低下 |
| 過剰に詳細なスキーマ | 一見すると安全 | 変更不能による技術的負債 |
| バージョニング不在 | 運用が簡単 | 下流障害の連鎖 |
さらに見落とされがちなのが、明示的なバージョニング戦略の欠如です。ODCS v3.xではバージョン管理が前提条件として組み込まれていますが、これを採用していない組織では、破壊的変更が静かに下流へ伝播します。Monte Carloが示す調査でも、重大なデータ障害の多くは「いつの間にか変わっていた」仕様変更に起因しており、後方互換性を考慮しない変更は最もコストの高い失敗要因とされています。
最後に、2026年特有の新しいアンチパターンとして、CDCへの過度な依存が挙げられます。Change Data Captureは便利ですが、データベース内部構造をそのまま下流に露出させるため、アプリケーションの軽微なリファクタリングが即座に契約違反となります。Redditのデータエンジニアリングコミュニティでも、CDCは補助的手段として位置付け、最終的には明示的なイベントとデータコントラクトへ移行すべきだという見解が主流になっています。
データコントラクトの失敗は、技術選定よりも設計思想と運用設計で決まります。実装前にこれらのアンチパターンを理解し、強制・最小・進化可能という原則を守れるかどうかが、成功と失敗を分ける分岐点になります。
Open Data Contract Standard(ODCS)と標準化の最新動向
データコントラクトがエンタープライズ基盤に定着するにつれ、最大の課題として浮上したのがツール間・組織間の非互換性でした。この問題に対する実践的な解として、2026年現在、Open Data Contract Standard(ODCS)が事実上の共通言語として急速に存在感を高めています。**ODCSは単なるフォーマット仕様ではなく、データをプロダクトとして流通させるための最低限の約束事を定義する標準**です。
ODCSはLinux Foundation傘下で進められているBitolプロジェクトによって策定されており、特定ベンダーに依存しない中立性が評価されています。GartnerやForresterが繰り返し指摘してきた「ガバナンスのベンダーロックイン問題」に対し、ODCSは構造レベルでの回避策を提示した形です。2025年から2026年にかけて主流となったv3系では、相互運用性を実運用で成立させるための設計が一段と洗練されました。
| 観点 | v2系まで | v3.x(2026年) |
|---|---|---|
| 記述形式 | JSON中心 | YAMLを正式採用 |
| 関係性定義 | 単一データセット前提 | ドメイン横断の依存関係を明示 |
| 想定用途 | ドキュメント共有 | CI/CDによる自動検証・強制 |
特に重要なのが、YAMLベースへの移行です。これにより、ソフトウェアエンジニアがAPI仕様を管理するのと同じ感覚で、Git上でデータコントラクトをレビューし、差分を議論できるようになりました。dbtやGable.ai、IBMのData Product HubなどがODCSをネイティブサポートしたことで、**標準に準拠するだけで複数ツールを横断したガバナンスが成立する環境**が現実のものとなっています。
またv3.xで追加された「Relationships」の概念は、データメッシュや分散分析基盤において決定的な意味を持ちます。従来は暗黙的だった結合キーや依存関係を契約として明示することで、変更時の影響範囲を機械的に検証できるようになりました。Bitolの公開資料によれば、この仕組みは大規模組織におけるデータ障害の初動対応時間を大幅に短縮するとされています。
標準化の本質的な価値は、ルールを縛ることではなく、選択の自由度を高める点にあります。ODCSに準拠することで、企業は特定ツールの思想に縛られず、将来の技術刷新やM&Aにも耐えうるデータ契約を維持できます。**2026年時点でODCSは、データコントラクトを一過性の施策から持続可能な経営インフラへ昇華させるための基盤**として、確実に標準の座を固めつつあります。
2026年版ツールエコシステム:強制型と可観測性型の違い
2026年のデータコントラクト関連ツールは、大きく「強制型」と「可観測性型」という二つの思想に分化しています。両者の違いは単なる機能差ではなく、データ品質をどのタイミングで、どこまで担保するのかという設計哲学そのものにあります。
強制型ツールは、問題が発生してから検知するのではなく、そもそも問題のあるデータを流さないことを目的としています。CI/CDやデプロイプロセスの中でデータコントラクトを検証し、違反があれば処理を停止します。Gable.aiやdbtのModel Contractsが代表例で、Git上のプルリクエストやモデル定義の段階でチェックが走るため、アプリケーションコードと同じ厳格さでデータ仕様を管理できます。
一方の可観測性型ツールは、データが生成・配信された後の世界を対象とします。Monte CarloやAtlanに代表されるこの系譜は、スキーマ変更、鮮度低下、分布の歪みといった異常を常時監視し、異変が起きた事実とその影響範囲を即座に可視化することに価値を置いています。ガートナーやForresterの分析でも、データ障害対応時間の短縮においてオブザーバビリティの有効性が指摘されています。
| 観点 | 強制型ツール | 可観測性型ツール |
|---|---|---|
| 主な検証タイミング | デプロイ前・ロード前 | ロード後・運用中 |
| 目的 | 違反の未然防止 | 影響把握と迅速な復旧 |
| 代表的な価値 | データダウンタイムの根絶 | 原因特定と説明責任 |
2026年時点で明確になっているのは、強制型だけ、あるいは可観測性型だけでは不十分という点です。dbt LabsがCoalesce 2025で示した試算では、強制型によるシフトレフトを徹底することでクラウド実行コストを約30%削減できる一方、完全なゼロ障害は現実的ではなく、運用段階での可視化が不可欠だとされています。
実際、Glassdoorの事例ではGable.aiによる事前強制と、下流での監視を組み合わせることで、障害対応がリアクティブからプロアクティブへと転換しました。コントラクト違反はDLQに隔離され、本番データは守られますが、同時に可観測性ツールが「もし通過していたら、どのダッシュボードやMLモデルに影響したか」を示します。この二層構えが、経営層への説明力を飛躍的に高めたと報告されています。
重要なのは、ツール選定を機能比較で終わらせないことです。自社が防ぎたいリスクは未然防止なのか、影響把握なのか、あるいはその両方なのかを明確にした上で、強制型と可観測性型を役割分担させる設計が、2026年のベストプラクティスになりつつあります。
GlassdoorやGoCardlessに学ぶ実装事例とROI
データコントラクトの価値は、理論ではなく実装後の成果によって評価されます。GlassdoorとGoCardlessの事例は、データ品質の向上がどのようにROIへ直結するのかを具体的に示しています。
まずGlassdoorは、数ペタバイト規模のデータを扱う中で、スキーマ変更に起因するETL停止やMLモデルの不整合が頻発し、エンジニアが事後対応に追われる状況に陥っていました。
同社はGable.aiを採用し、CI/CDパイプライン上でデータコントラクトを静的解析し、Kafka Schema RegistryとWAPパターンを組み合わせることで、本番投入前に違反を検知・隔離する仕組みを構築しました。
Gableの公開事例によれば、違反データはDead Letter Queueに自動退避され、本番環境の汚染を防止しています。これにより、障害対応の工数が大幅に減少し、プロダクト開発チームとデータチーム間の摩擦も解消されました。
リアクティブからプロアクティブへの転換が、運用効率と組織文化の両面で効果を生んだ点が重要です。
| 企業 | 主な実装ポイント | ビジネス効果 |
|---|---|---|
| Glassdoor | CI/CDでの静的解析とDLQ隔離 | 障害削減と開発効率向上 |
| GoCardless | コントラクトを起点に自動プロビジョニング | リードタイム短縮と統制強化 |
一方、英国のFinTech企業GoCardlessは、データコントラクトを品質管理に留めず、インフラ自動化の設計図として活用しました。
Jsonette形式のコントラクトをGitにマージすると、BigQueryのデータセット、Pub/Subトピック、IAM設定までが自動的に構築される社内基盤「Utopia」を整備しています。
この仕組みにより、基盤構築のリードタイムが短縮されただけでなく、GDPRの削除要求などコンプライアンス対応もコントラクトベースで自動化されました。
ROIの観点では、Nucleus Researchが報告したMatillion社のCLM事例における4,062%という数値が示すように、契約をコード化し手作業を排除する投資は極めて高い回収効果を持ちます。
データ分野でも同様に、1-10-100の法則が示す通り、問題を発生源で抑止できるデータコントラクトは、修正コストと機会損失を同時に削減する戦略的施策として位置づけられています。
生成AI・RAG時代に拡張されるセマンティック・データコントラクト
生成AIとRAGの本格導入が進んだ2026年、データコントラクトは構造保証の仕組みから、意味そのものを保証する仕組みへと拡張されています。特に注目されているのが、セマンティック・データコントラクトです。これは、AIが参照・理解・生成する情報の意味的整合性を契約として明示し、品質を担保する新しいガバナンスの形です。
RAGシステムでは、PDF、FAQ、議事録、チャットログといった非構造化データが知識源になります。このとき、スキーマ定義だけでは不十分で、内容が最新か、前提条件が正しいか、文脈が一貫しているかといった意味的品質が直接AIの回答精度に影響します。**セマンティック・データコントラクトは、この曖昧だった領域を定量的・検証可能な契約へと変換します。**
| 観点 | 従来のデータコントラクト | セマンティック・データコントラクト |
|---|---|---|
| 対象 | 構造化データ | 非構造化・半構造化データ |
| 品質指標 | 型、Null制約、鮮度 | 意味整合性、検索再現率、幻覚率 |
| 主な利用先 | BI、ETL、ML | LLM、RAG、AIエージェント |
具体的には、Embedding QualityやRecall@K、Hallucination Rateといった指標がSLAとして定義されます。たとえば「Top5検索結果で80%以上の再現率」「回答に含まれる事実誤認は2%未満」といった条件を満たさない場合、そのドキュメントは自動的にインデックス対象から除外されます。これはAtlanやMonte Carloが提唱するAI対応データガバナンスの考え方とも一致しています。
また重要なのが、AIリネージの概念です。どのドキュメントが、どのEmbeddingを経由し、どの回答生成に使われたのかを追跡可能にすることで、なぜその回答に至ったのかを説明できます。World Wide Technologyの分析でも、**説明可能性を欠いたAIは企業利用に耐えない**と指摘されています。
先行企業では、法務ナレッジや製品仕様書にこの契約を適用し、古い情報や地域限定ルールが混入した回答を防いでいます。EA Journalsに掲載された研究でも、意味的制約を導入したRAGは、未導入の場合と比べて誤回答率が大幅に低下したと報告されています。
生成AI時代において、データ品質とは正確さだけでなく、意味の一貫性と利用文脈への適合性を含みます。**セマンティック・データコントラクトは、AIにとっての信頼できる知識の境界線を定義する契約**として、今後のエンタープライズAIの成否を左右する重要な要素になりつつあります。
日本企業における受容性と導入を成功させるための戦略
日本企業でデータコントラクトを定着させるためには、技術論よりも先に組織的な受容性を高める設計が不可欠です。経済産業省のAI・データ契約ガイドラインでも示されている通り、日本企業は暗黙知よりも明示的な合意や仕様を重視する文化を持っています。この特性は、**合意内容をコードとして強制できるデータコントラクトと本質的に相性が良い**一方、運用を誤ると官僚的プロセスに陥るリスクも孕んでいます。
導入初期で最も重要なのは、全社横断の理想像を掲げることではなく、ビジネスインパクトが即座に可視化される領域に限定することです。Monte CarloやGable.aiのユーザー事例が示すように、マーケティング指標や不正検知など、数値の信頼性が直接収益やリスクに直結する領域では、データ品質改善の効果が短期間で認識されやすく、現場の納得感を得やすいです。**スモールスタートによる成功体験の蓄積が、横展開の最大の推進力になります。**
もう一つの鍵は、承認フローの再設計です。日本企業では変更管理に稟議や多段承認が伴うことが一般的ですが、データコントラクトにそれをそのまま適用すると開発速度が著しく低下します。先進企業では、ODCS準拠のコントラクト変更をGit上のプルリクエストに集約し、CI/CDによる自動検証を一次承認と見なす運用が広がっています。Linux FoundationのBitolプロジェクトが示す標準化の方向性も、こうした自動承認モデルを前提としています。
| 日本企業特有の課題 | 有効なデータコントラクト戦略 | 期待される効果 |
|---|---|---|
| 部門サイロと責任の曖昧さ | データオーナーをコントラクトに明記 | 問い合わせ・調整コストの削減 |
| 承認プロセスの肥大化 | CI/CDによる自動検証を承認に代替 | 変更リードタイムの短縮 |
| 品質責任の下流集中 | シフトレフト型コントラクト導入 | データダウンタイムの予防 |
さらに重要なのは、人材と評価制度です。データコントラクトを「統制のためのルール」と捉えさせてしまうと反発が生まれます。dbt LabsやGableの提唱するData as a Productの思想にならい、**データ品質をコード品質の一部として評価する文化を醸成することが、長期的な成功要因**となります。これは技術導入ではなく、経営と現場をつなぐ変革マネジメントそのものです。
参考文献
- Splunk:Data Trends in 2026: 8 Trends To Follow
- Atlan:Data Contracts Explained: Key Aspects, Tools, Setup in 2026
- Bitol (Linux Foundation):Open Data Contract Standard v3.1.0
- Gable.ai Blog:Shifting From Reactive to Proactive at Glassdoor
- dbt Labs:Coalesce 2025: Rewriting the future of data, analytics, and AI
- EA Journals:Semantic Data Contracts: A New Integration Paradigm for Enterprise AI and Database Systems
- Global Legal Insights:AI, Machine Learning & Big Data Laws 2025 | Japan